This blog post was originally published in November 2017 and was updated in June 2023.
In this blog, we’ll provide a comparison between MariaDB vs. MySQL (including Percona Server for MySQL).
Introduction: MariaDB vs. MySQL
The goal of this blog post is to evaluate, at a higher level, MariaDB vs. MySQL vs. Percona Server for MySQL side-by-side to better inform the decision making process. It is largely an unofficial response to published comments from the MariaDB Corporation.
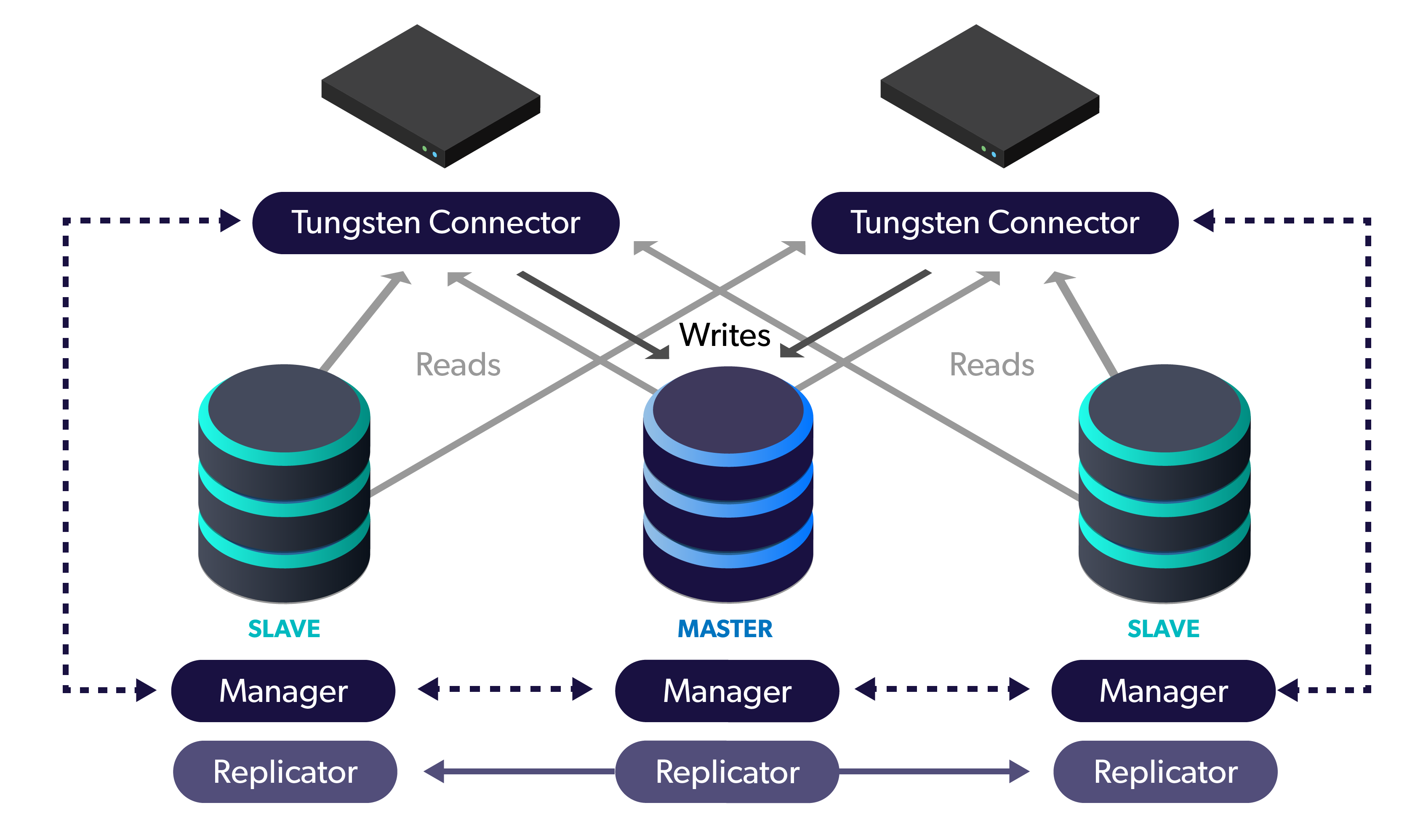
It is worth noting that Percona Server for MySQL is a drop-in compatible branch of MySQL, where Percona contributes as much as possible upstream. MariaDB Server, on the other hand, is a fork of MySQL 5.5. They cherry-picked MySQL features and don’t …
[Read more]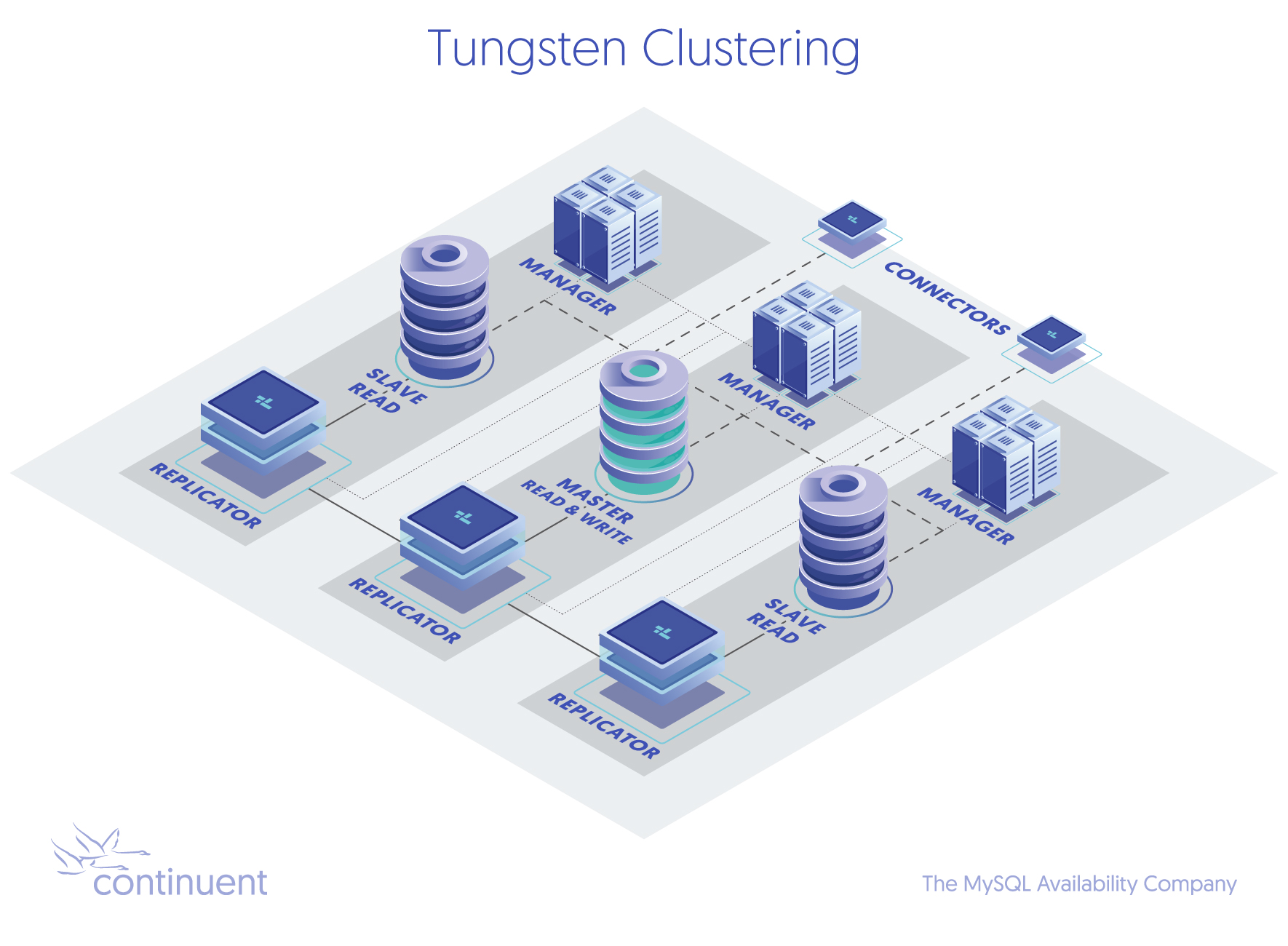{kind=link}
{kind=link}
{kind=link}