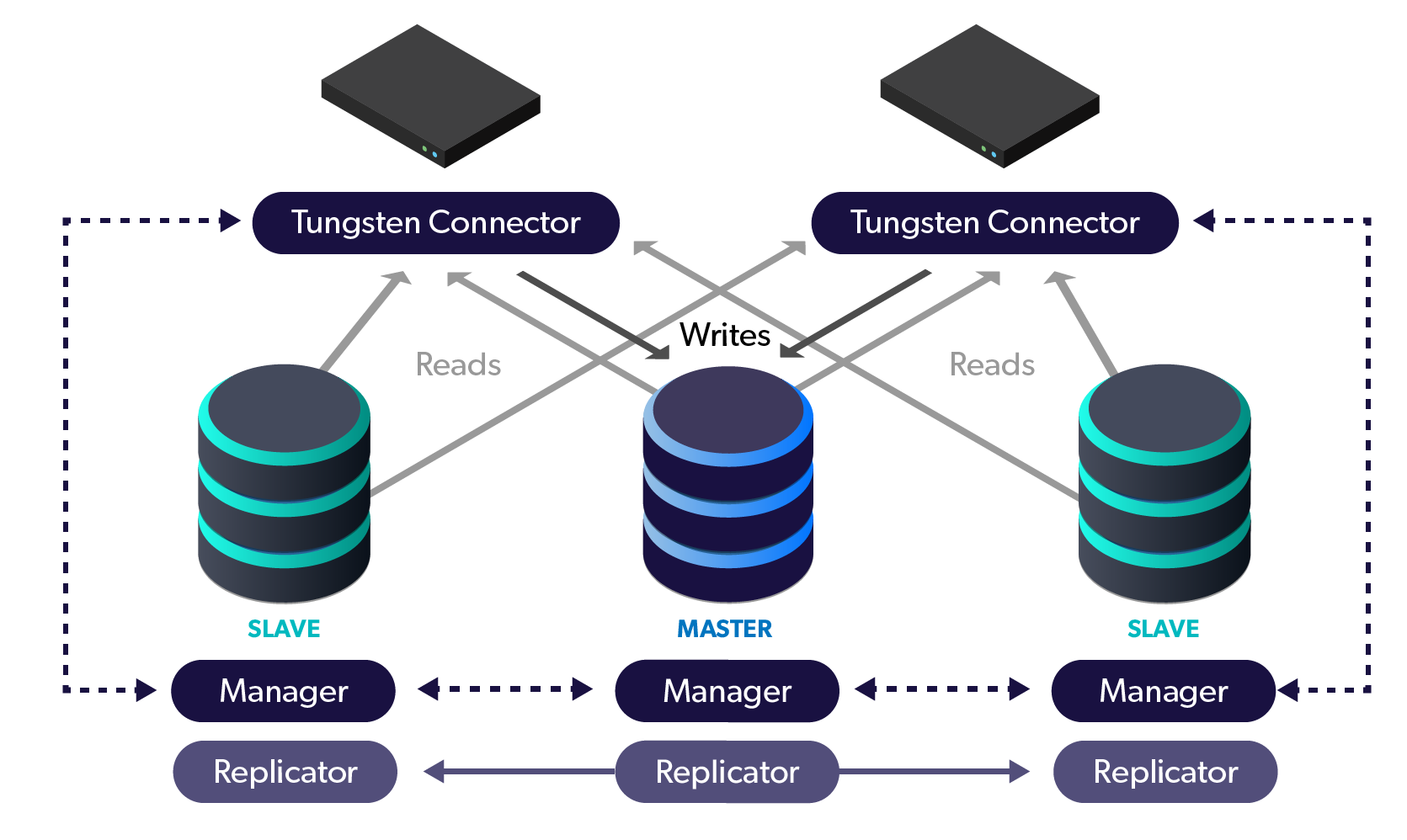
The Question Recently, a customer asked us:
What would cause a node switch to fail in a Tungsten Cluster?
For example, we saw the following during a recent session where a
switch failed:
cctrl> switch to db3 SELECTED SLAVE: db3@alpha SET POLICY: MAINTENANCE => MAINTENANCE PURGE REMAINING ACTIVE SESSIONS ON CURRENT MASTER 'db1@alpha' PURGED A TOTAL OF 0 ACTIVE SESSIONS ON MASTER 'db1@alpha' FLUSH TRANSACTIONS ON CURRENT MASTER 'db1@alpha' Exception encountered during SWITCH. Failed while setting the replicator 'db1' role to 'slave' ClusterManagerException: Exception while executing command 'replicatorStatus' on manager 'db1' Exception=Failed to execute '/alpha/db1/manager/ClusterManagementHelper/replicatorStatus alpha db3' Reason= CLUSTER_MEMBER(true) STATUS(FAIL) +----------------------------------------------------------------------------+ |alpha | …[Read more]
{kind=link}
{kind=link}