In our earlier post, we unpacked the mechanics of MySQL HeatWave maintenance, the behind-the-scenes process that keeps your MySQL environments secure, stable, and optimized without changing your database version. We also touched on how Auto Minor Version Upgrades occur when a version reaches the end of its lifecycle. With this update, MySQL HeatWave introduces Configurable Maintenance Windows and Auto-Upgrade Controls, giving you […]
Nov
17
2025
Dec
17
2019
Zero Downtime SaaS Provider — How to Easily Deploy MySQL Clusters in AWS and Recover from Multi-Zone AWS Outages
This is the second post in a series of blogs in which we cover a number of different Continuent Tungsten customer use cases that center around achieving continuous MySQL operations with commercial-grade high availability (HA), geographically redundant disaster recovery (DR) and global scaling – and how we help our customers achieve this.
This use case looks at a multi-year (since 2012) Continent customer who is a large Florida-based SaaS provider dealing with sensitive (HIPAA Compliant) medical data, which offers electronic health records, practice management, revenue cycle management and data analytics for thousands of doctors.
What is the Challenge?
Lack of high availability in AWS. The challenge they were facing came from using AWS, which allowed them to rapidly provision database and …
[Read more]
Aug
29
2019
Why does the DIY approach fail to deliver vs. the Tungsten Clustering solution for geo-distributed MySQL multimaster deployments?
Before we dive into the 10 reasons, note why commercially-supported enterprise software is less risky and in fact less costly:
- The labor time spent building and maintaining a DIY solution costs more than a supported solution that just works.
- There is documentation, training, support, so your mission-critical process is never dependent upon an irreplaceable individual.
-
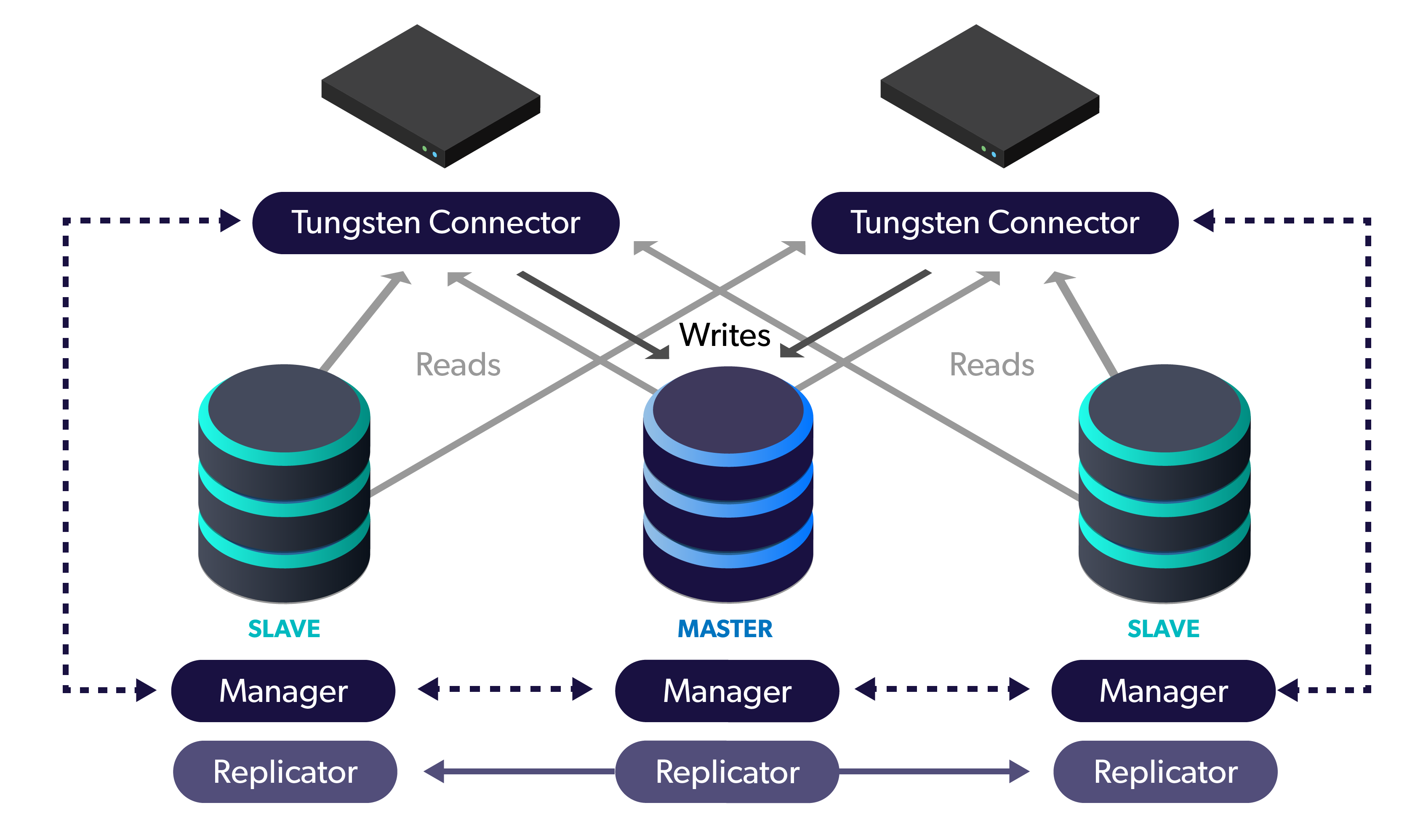
Tungsten Clustering is a complete
solution, comprised of the Replicator, Manager and Connector
components
- With DIY, you must first decide the architecture, then select the individual tools to handle each layer of the topology. …
{kind=link}
Aug
26
2019
{kind=link}
Overview The Skinny
Part of the power of Tungsten Clustering for MySQL / MariaDB is the ability to perform true zero-downtime maintenance, allowing client applications full access to the database layer, while taking out individual nodes for maintenance and upgrades. In this blog post we cover various types of maintenance scenarios, the best practices associated with each type of action, and the key steps to ensure the highest availability.
Important Questions Understand the Environment as a Whole First
There are a number of questions to ask when planning cluster maintenance that are critical to understand before starting.
For example:
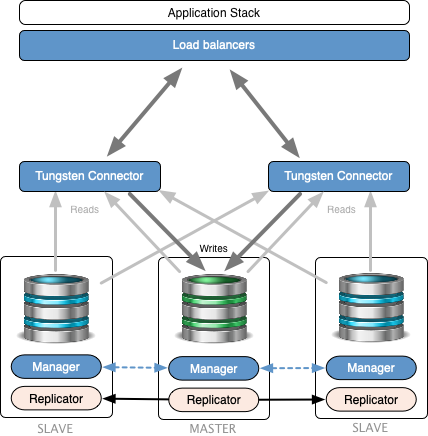
- What is the cluster topology?
-
Standalone (connectors write to single
cluster master)
Single cluster: …
-
Standalone (connectors write to single
cluster master)
Jul
25
2019
The Question Recently, a customer asked us:
How would we manually move the relay role from a failing node to a slave in a Composite Tungsten Cluster passive site?
The Answer The Long and the Short of It
There are two ways to handle this procedure manually when the
usual switch command fails to work as expected. One
is short and reasonably automated, and the other is much more
detailed and manual.
Of course, the usual procedure is to just issue the
switch command in the passive cluster:
use west set policy maintenance switch set policy automatic
The below article describes what to do when the
switch command does not move the relay role to
another node.
SHORT
Below is the list of cctrl commands that would be run for the basic, short version, which (aside from handling policy changes) is really only three …
[Read more]
Jun
11
2019
{kind=link}
Overview The Skinny
When it comes to zero downtime, proxies are the first line components of a cluster.
In order to achieve High Availability (HA) for MySQL, MariaDB and Percona Server, a commonly deployed setup consists of configuring load balancers (hardware or software) on top of those proxies.
A Strong Architecture How is Maintenance Made Possible?
With this proxy + load balancer architecture, server maintenance is made possible on any of the proxy hosts, as follows:
- the proxy is stopped
- the load balancer detects the dead proxy and removes it from the pool
- new connection requests go to live proxies
The Problem What Happens to Existing Sessions?
But wait… even though new connections are re-routed correctly, what happens …
[Read more]
Jun
09
2019
How to properly shutdown MySQL before any maintenance activity
We might have different scenarios once we need to stop MySQL
service before performing either server or database activity like
patching/upgrade.
Before performing such activity, we need to make sure that we
stop MySQL service properly to avoid any unforeseen crashes once
our maintenance activity complete and MySQL service is
started.
Here I would like to share the below steps which should be
performed and take care to properly stop MySQL
service.
{kind=link}
Step 1: Ensure we don't have any long-running queries. Manually verify by checking the processlist. show …
[Read more]
Nov
02
2018
Recently, I’ve been working with a customer to evaluate the different cloud solutions for MySQL. In this post I am going to focus on maintenance windows and requirements, and what the different cloud platforms offer.
Why is this important at all?
Maintenance windows are required so that the cloud provider can do the necessary updates, patches, and changes to our setup. But there are many questions like:
- Is this going to impact our production traffic?
- Is this going to cause any downtime?
- How long does it take?
- Any way to avoid it?
Let’s discuss the three most popular cloud provider: AWS, Google, Microsoft. These three each have a MySQL based database service where we can compare the maintenance settings.
AWS
When you create an instance you can define your maintenance window. It’s a 30 minutes block when AWS can update and restart …
[Read more]
Oct
23
2018
Recently we had a customer that had issues with a filled disk on the server hosting their Docker pmm-server environment. They were not able to access the web UI, or even stop the pmm-server container because they had filled the /var/ mount point.
Setting correct expectations
The best way to avoid these kinds of issues in the first place is to plan ahead, and to know exactly with what you are dealing with in terms of disk space requirements. Michael Coburn has written a great blogpost on this matter:
We are now using …
[Read more]
Sep
25
2018
Continuent Clustering support true distributed multimaster clustering. In this topology, there are cross-site replicator services for each remote site. In a 3-site configuration, there are a total of 9 replication streams to manage.
Continuent Clustering also offers a graphical administration tool called the Tungsten Dashboard to help with your management burden. The GUI makes the deployment much easier to visualize and administer.
For our example, we will have a Composite Multimaster dataservice called global with three active, writable member clusters (one per site), east, west and north.
Dashboard Summary View
In the summary, collapsed view, the composite service and all member clusters are listed with associated information and controls. Note that the Type for the composite dataservice global is CompMM …
[Read more]