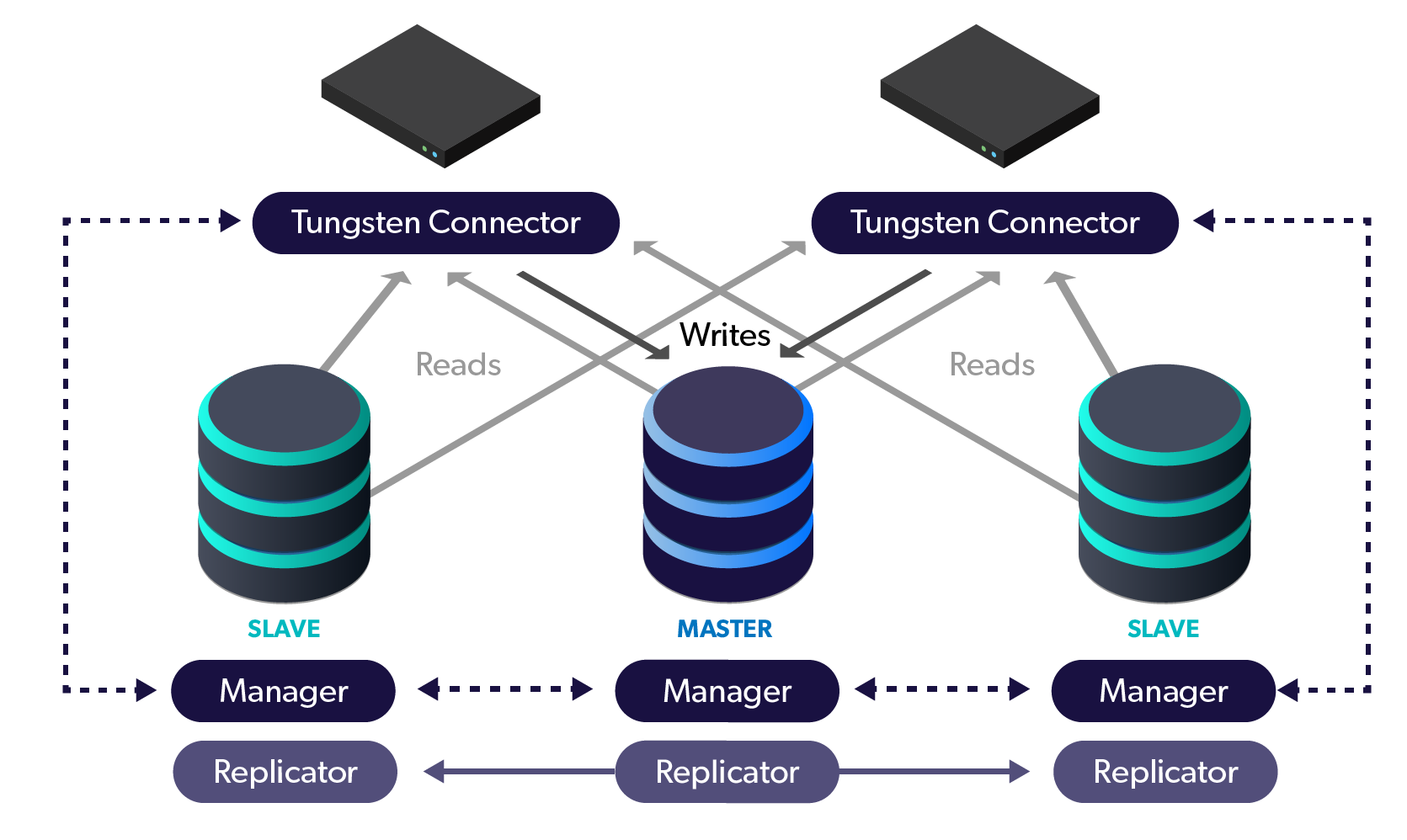
Your database cluster contains your most business-critical data and therefore proper performance under load is critical to business health. If response time is slow, customers (and staff) get frustrated and the business suffers a slow-down.
{kind=link}
If the database layer is unable to keep up with demand, all applications can and will suffer slow performance as a result.
To prevent this situation, use load tests to determine the throughput as objectively as possible.
In the sample load.pl script below, increase load by
increasing the thread quantity.
You could also run this on a database with data in it without polluting the existing data since new test databases are created to match each node’s hostname for uniqueness.
Note: The examples in this blog post assume that a Connector is …
[Read more]