Just recently, I have been asked to look into what a Disaster Recovery site for InnoDB Cluster would look like.
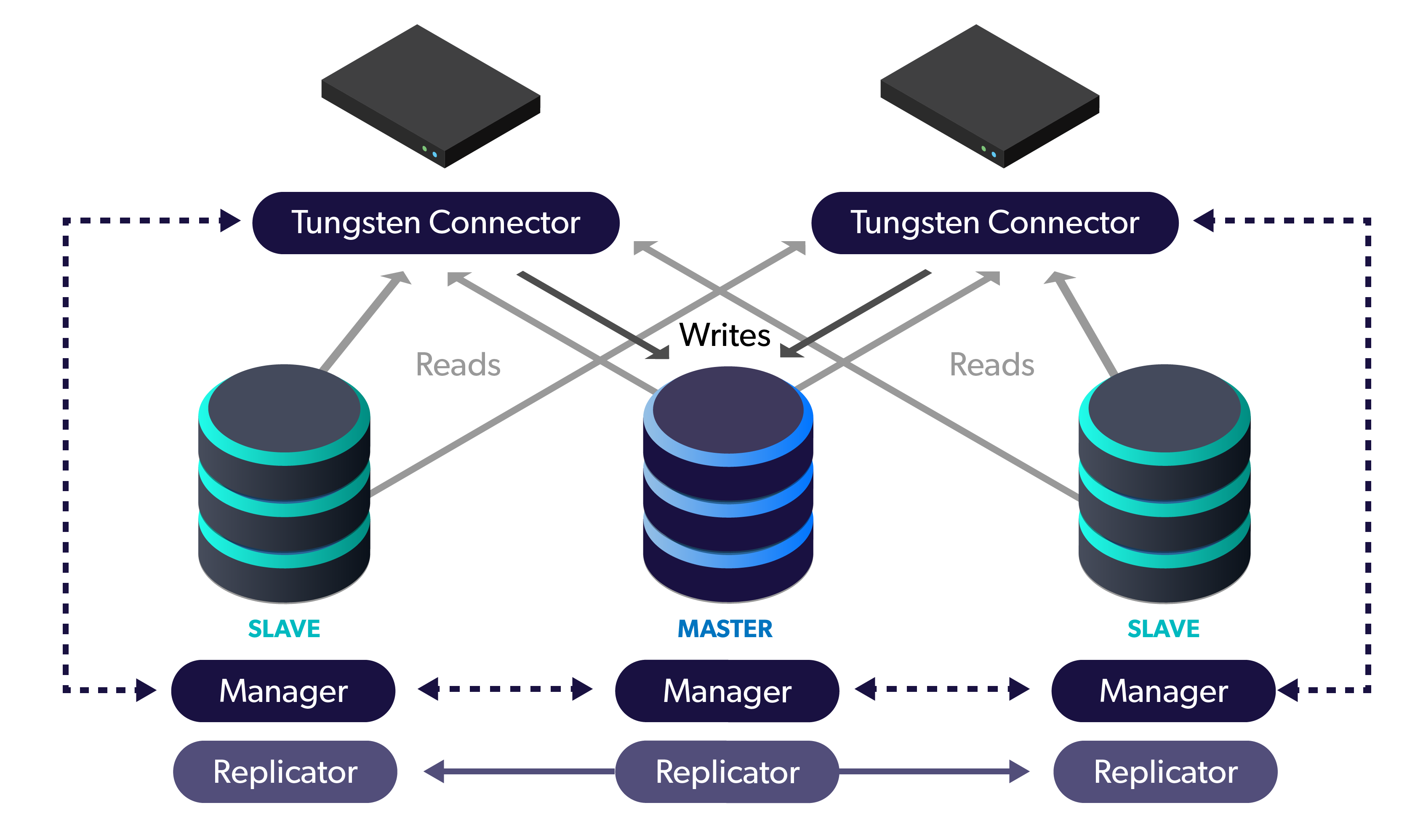
If you’re reading this, then I assume you’re familiar with what MySQL InnoDB Cluster is, and how it is configured, components, etc.
Reminder: InnoDB Cluster (Group Replication, Shell & Router) in version 8.0 has had serious improvements from 5.7. Please try it out.
So, given that, and given that we want to consider how best to fulfill the need, i.e. create a DR site for our InnoDB Cluster, let’s get started.
Basically I’ll be looking at the following scenario:
InnoDB Cluster Source site with a Group Replication Disaster Recovery Site.
Now, just before we get into the nitty-gritty, here’s the scope.
Life is already hard enough, so we want as much automated as possible, so, yes, InnoDB Cluster gets some of that done, but there are other parts we will still have to …
[Read more]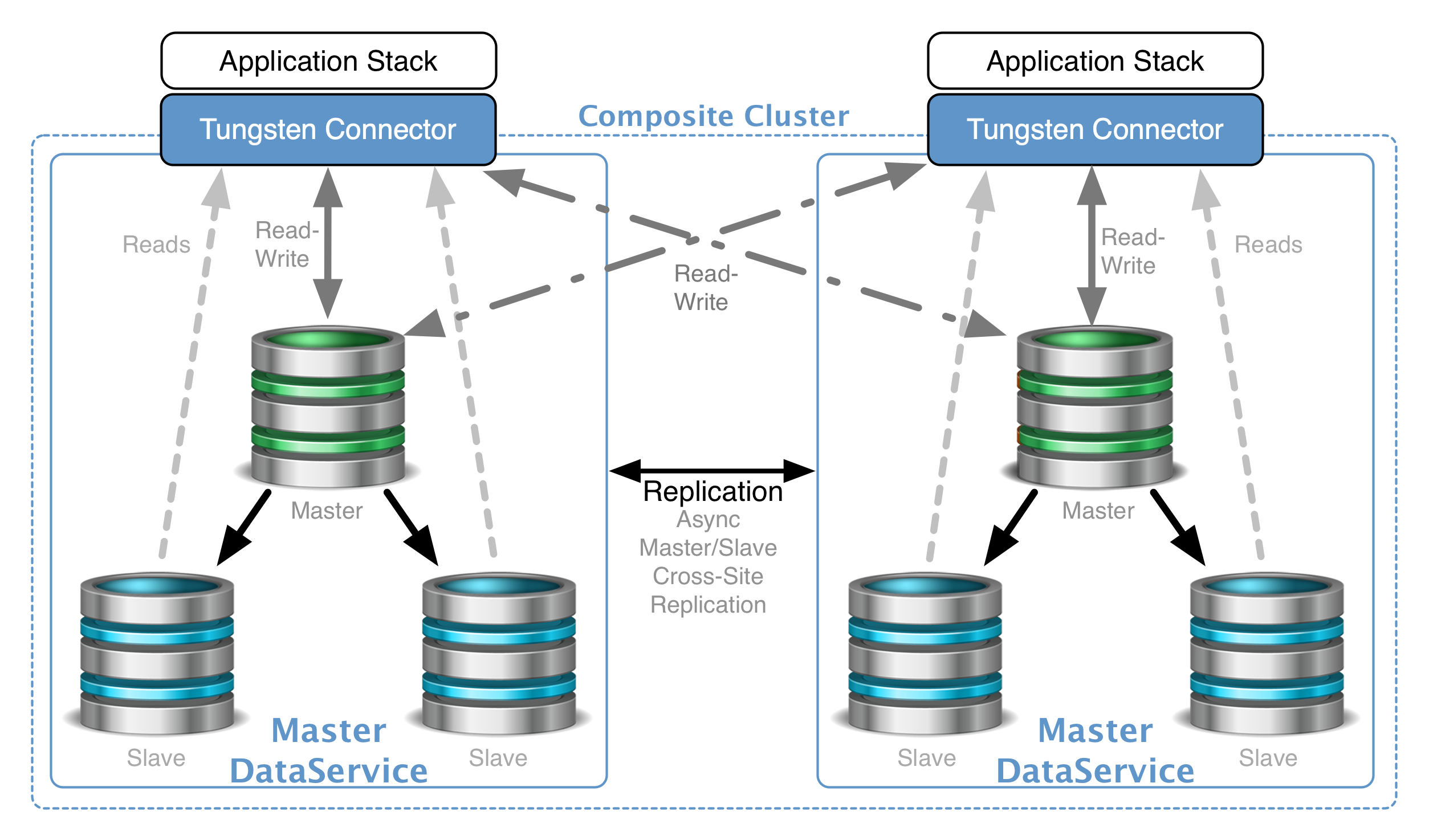{kind=link}
{kind=link}
{kind=link}