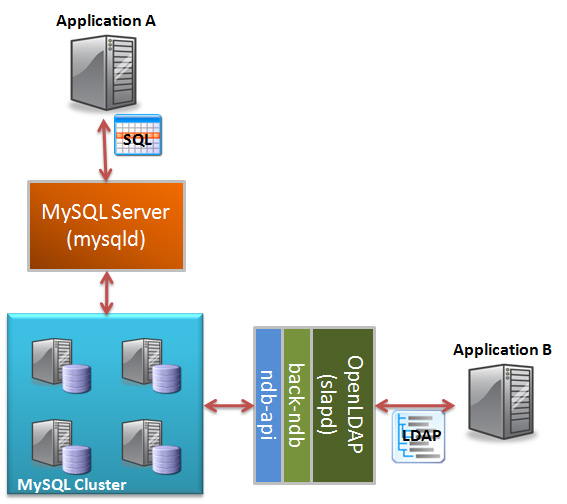
This post describes how MySQL Cluster executes queries. First of
all, Cluster is a storage engine. It doesn't actually execute
queries because it doesn't speak SQL. That is why you use a MySQL
server, which parses your queries and sends low-level storage
engine API calls to the Cluster data nodes. The data nodes know
how to retrieve or store data. Or you can talk to the data nodes
directly using the NDB API(s).
MySQL Cluster has various means of executing queries. They boil
down to:
- Primary key lookup
- Unique key lookup
- Ordered index scan (i.e., non-unique indexes that use T-trees)
- Full table scan
Let's say you have 4 data nodes in your cluster (NoOfReplicas=2).
This means you have 2 node groups and each one has half the data.
Cluster uses a hash on the primary key (unless you've controlled
the partitioning using the 5.1 partitioning features). So for …
{kind=link}