MySQL is taking a significant step forward by rethinking how foreign key constraints and cascades are managed. Starting with MySQL 9.6, foreign key checks and cascade operations will be handled directly by the SQL engine rather than the InnoDB storage engine. This improvement addresses long-standing challenges with change tracking, binary log replication, and data consistency, making […]
Jan
30
2026
Jul
22
2024
pt-online-schema-change is an amazing tool for assisting in table modifications in cases where ONLINE ALTER is not an option. But if you have foreign keys, this could be an interesting and important read for you. Tables with foreign keys are always complicated, and they have to be handled with care. The use case I am […]
Jun
15
2021
This post explains the inherent problem of running online schema changes in MySQL, on tables participating in a foreign key relationship. We'll lay some ground rules and facts, sketch a simplified schema, and dive into an online schema change operation. Our discussion applies to gh-ost, pt-online-schema-change, and VReplication based migrations, or any other online schema change tool that works with a shadow/ghost table like the Facebook tools. Why Online DDL? # Online schema change tools come as workarounds to an old problem: schema migrations in MySQL were blocking, uninterruptible, aggressive in resources, replication unfriendly.
Nov
11
2018
The other day, I was reading a blog by Magnus Hagander about tracking foreign keys throughout a schema in PostgreSQL. I thought it was a good idea, so I decided to look at how you can track foreign key in MySQL.
The way I decided to do it was to start out with a table, then
find all tables referencing the table by a foreign key. From this
basic (and simple as it will be shown) query, it is possible to
create a chain of relations. The key table for the queries is
…
Sep
06
2016
Introduction
This is the final installment of a five part blog series to explore InnoDB internals by looking at the related tunable system variables. In this section we’re going to cover variables that relate to enforcing data consistency, and how index statistics are handled and stored.
Just like previous sections, I would like to emphasize something that was written in part one of this blog post series.
“I should note that while tuning recommendations are provided, this objective of this blog post series was NOT meant to be a tuning primer, but instead to explore the mechanics that each variable interacts with. As such I would like to advise against reading this guide and trying to fine tune all of the available InnoDB variables. System variable tuning is an exercise in diminishing returns, the most benefit you’ll get out of tuning your MySQL server will occur within the first 15 minutes of configuration. In …
[Read more]
May
13
2014
Foreign Keys are often a mystery to new DBAs in the MySQL world. Hopefully this blog will clear some of this up.
In this example, we will have a table for employee data and a
table for the data on offices. First we need the two
tables.
CREATE TABLE employee (
-> e_id INT NOT NULL,
-> name CHAR(20),
-> PRIMARY KEY (e_id)
-> );
CREATE TABLE building (
-> office_nbr INT NOT NULL,
-> description CHAR(20),
-> e_id INT NOT NULL,
-> PRIMARY KEY (office_nbr),
-> FOREIGN KEY (e_id)
-> REFERENCES employee (e_id)
-> ON UPDATE CASCADE
-> ON DELETE CASCADE);
Those who do not use Foreign Keys will not be familiar with the last four lines of the building table. The trick is that there are two e_id columns, one in each table. In the employee table …
[Read more]
Oct
14
2013
It's no secret that you shouldn't rely on replication filtering.
Recently a customer asked if an `ON DELETE CASCADE` would still
affect the data on a slave if the table was being ignored through
replication filtering. It was one of those occasions that I
couldn't give a confident answer without a quick test but alas
the gut was right and the obvious answer is yes, "ON
DELETE|UPDATE CASCADE" will change data even if you replicate
using replication filters.
I tested using RBR and SBR. If anything I was questioning the
behaviour of RBR here but it turns out to be consistent with SBR.
I had a master-slave setup already deployed for some other
testing so it was easy to implement the FKs needed for this. The
dataset is the trusty world db available from dev.mysql.com and I needed to change the
constraints on the table to match the conditions proposed.
Master …
Jun
20
2013
FOREIGN KEYs in MySQL Cluster is a big step
forward. It is now possible to run enterprise software with NDB
Cluster as the storage backend. Over the years, the lack of
FOREIGN KEYs have been one of the most limiting pieces of
functionality. Who wants to fiddle with TRIGGERs or recode
applications to enforce data integrity?
But finally, it is here. It is implemented natively at the Data
Node level, where NDB stores its data. It is well known that
FOREIGN KEYs come with an overhead. E.g., when writing a record
into a child table, the existence must be checked in the parent
table. Since data is distributed across multiple Data Nodes, the
child record and parent record may be on different nodes or
shards (Node Groups). Hence there is extra work to be done in
terms of internal triggers and network communication, the latter
being the more costly. The performance impact must be taken into
account when doing …
Jun
18
2013
{kind=link}
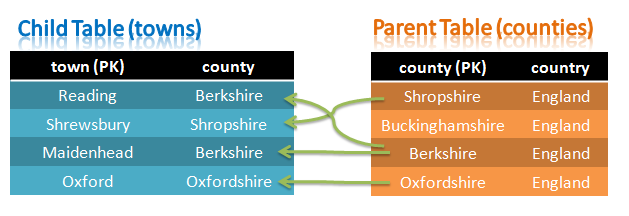
Foreign Key constraints between tables
The newly announced GA of MySQL Cluster 7.3 (7.3.2) builds upon second DMR (7.3.1 m2) released earlier in the year which added Foreign Keys to MySQL Cluster. Foreign Keys is a feature requested by many, many people and has often been cited as the reason for not being able to replace InnoDB with MySQL Cluster when they needed the extra availability or scalability.
Note that this post is an up-version of the original – and was first published with the 7.3 labs release in June 2012.
What’s a Foreign Key
The majority of readers who are already familiar with Foreign Keys can skip to the next section.
Foreign Keys are a way of implementing relationships/constraints between columns in different tables. For example, in the above figure, we want to make sure …
[Read more]
Nov
16
2010
Although MyISAM has been the default storage engine for MySQL but its soon going to change with the release of MySQL server 5.5. Not only that, more and more people are shifting over to the Innodb storage engine and the reasons for that is the tremendous benefits, not only in terms of performance, concurrency, ACID-transactions, foreign key constraints, but also because of the way it helps out the DBA with hot-backups support, automatic crash recovery and avoiding data inconsistencies which can prove to be a pain with MyISAM. In this article I try to hammer out the reasons why you should move on to using Innodb instead of MyISAM.