Overview The Skinny
In this blog post we will discuss how to best integrate various Continuent-bundled cluster monitoring solutions with PagerDuty (pagerduty.com), a popular alerting service.
Agenda What’s Here?
- Briefly explore the bundled cluster monitoring tools
- Describe the procedure for establishing alerting via PagerDuty
- Examine some of the multiple monitoring tools included with the Continuent Tungsten Clustering software, and provide examples of how to send an email to PagerDuty from each of the tools.
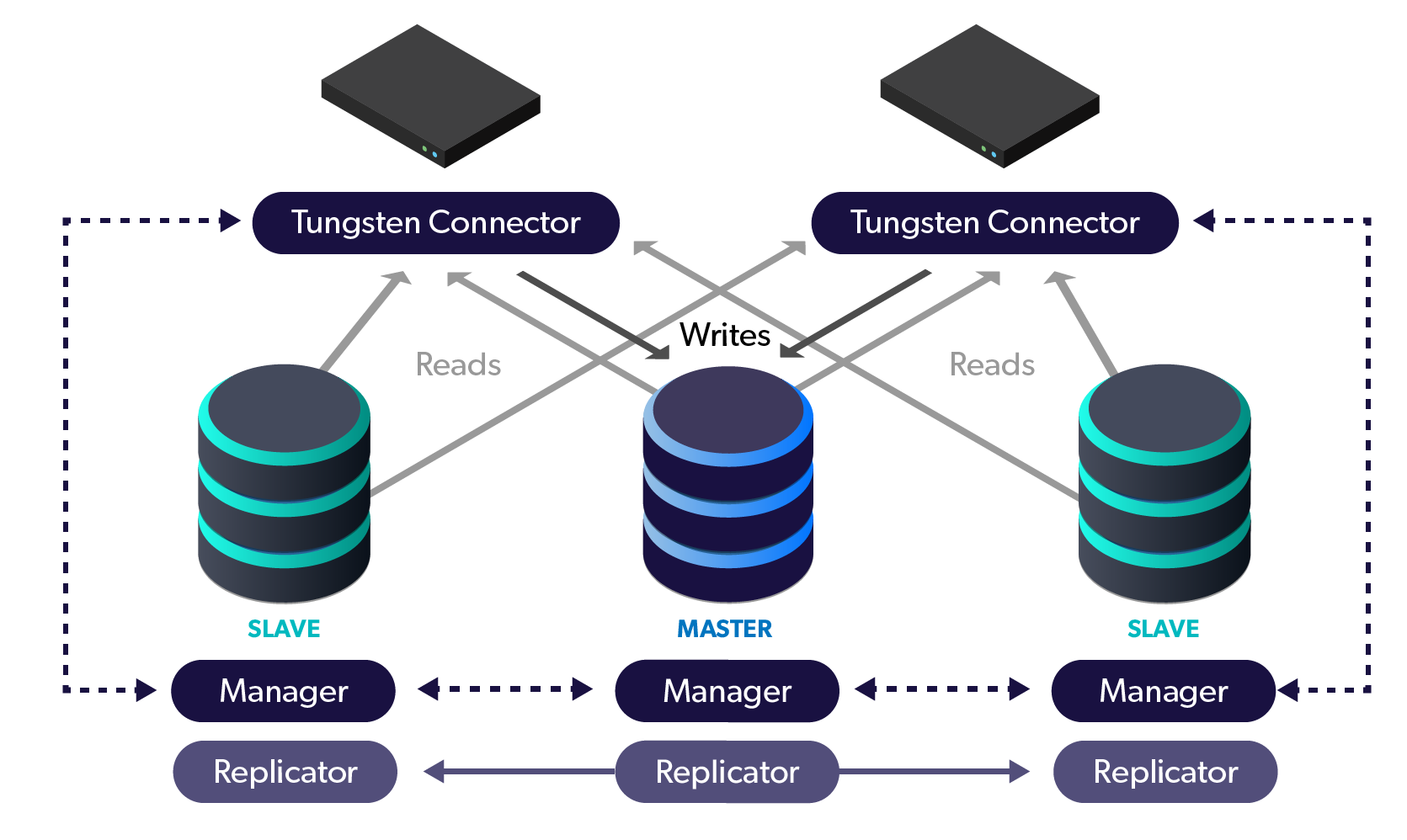
Exploring the Bundled Cluster Monitoring Tools A Brief Summary
Continuent provides multiple methods out of the box to monitor
the cluster health. The most popular is the suite of Nagios/NRPE
scripts (i.e. cluster-home/bin/check_tungsten_*). We
also have Zabbix scripts (i.e.
cluster-home/bin/zabbix_tungsten_*). Additionally,
there is …
{kind=link}
{kind=link}