In this post, we are going to show how to develop fault-tolerant
applications using MySQL Fabric, or simply Fabric, which
is an approach to building high availability sharding
solutions for MySQL and that has recently become available
for download as a labs release (http://labs.mysql.com/). We are going to focus
on Fabric's high availability aspects but to find out more on
sharding readers may check out the following blog post:
Servers managed by Fabric are registered in a MySQL Server instance, called backing store, and are …
[Read more]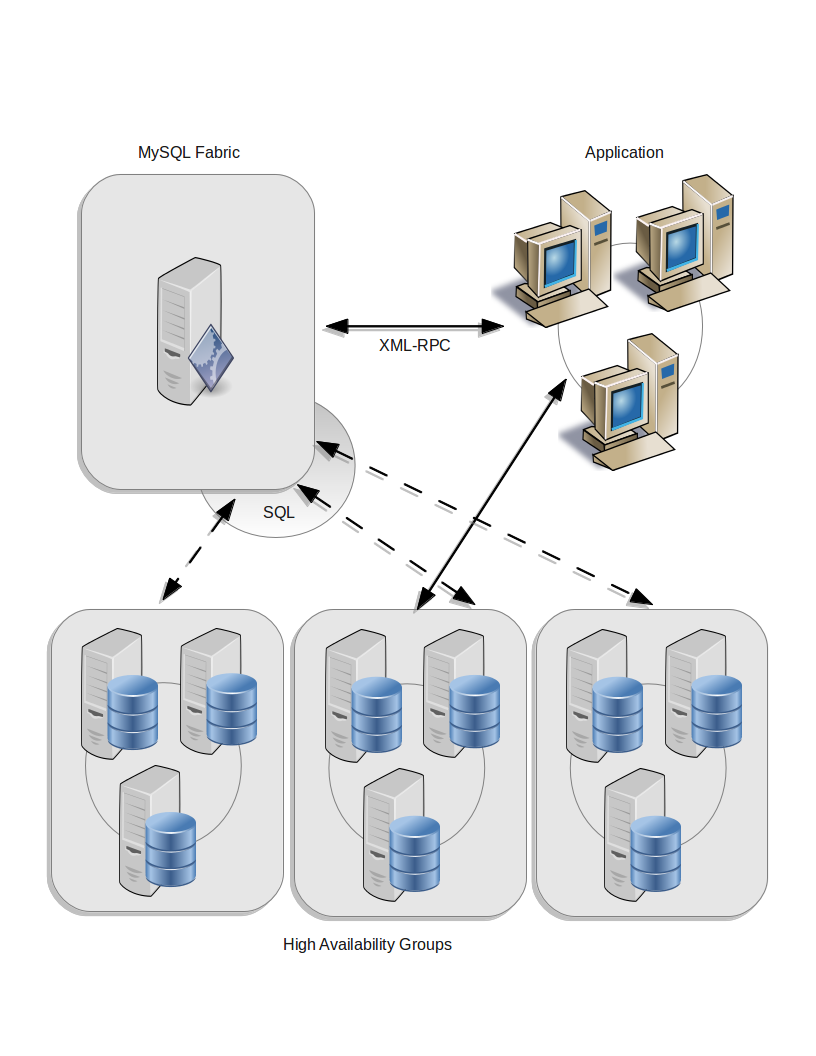{kind=link}