It's no secret that you shouldn't rely on replication filtering.
Recently a customer asked if an `ON DELETE CASCADE` would still
affect the data on a slave if the table was being ignored through
replication filtering. It was one of those occasions that I
couldn't give a confident answer without a quick test but alas
the gut was right and the obvious answer is yes, "ON
DELETE|UPDATE CASCADE" will change data even if you replicate
using replication filters.
I tested using RBR and SBR. If anything I was questioning the
behaviour of RBR here but it turns out to be consistent with SBR.
I had a master-slave setup already deployed for some other
testing so it was easy to implement the FKs needed for this. The
dataset is the trusty world db available from dev.mysql.com and I needed to change the
constraints on the table to match the conditions proposed.
Master …
MySQL Server 5.6 has seen fast adoption - the list of performance improvements and features make a convincing argument all on their own.
Join those adopting the MySQL database by taking the MySQL for Database Administrators training course.
This 5-day course teaches you all the core dba skills including what MySQL Server 5.6 brings you in terms of Replication. You will learn about:
- Managing the MySQL Binary Log
- MySQL replication threads and files
- Using MySQL Utilities for Replication
- Designing Complex Replication Topologies
- Multi-Master and Circular Replication …
Since I joined the company in late 2010, I have known that one of the strong points of Tungsten Replicator is its ability of setting filters. The amazing capabilities offered by Tungsten filters cannot be fully grasped unless we explain how stage replication works.
There are several default stages in the replication stream. Every stage has an extraction task and an apply task. The extraction task will get data from the previous step repository and the apply task will save the data to the next repository, which can be either a temporary storage (memory queue, THL file) or the final destination (slave database server). Consider that the architecture allows developers to add stages, and you will appreciate its full power. For every stage, we can insert one or more filter between the two tasks. …
[Read more]Send to Kindle
Last week, durring MySQL Connect, MySQL 5.7.2 DMR was launched, one of the new functionality is the multi source replication. At the moment, MySQL can have only one master per slave (you can archive multi source replication via some hacks, but like the name says, it’s a hack).
See how to configure here
To clarify, there is a difference between multi-master replication and multi source replication, see the bellow pictures to understand the difference:
{kind=link}
MySQL Multi Master Replication
Multi Master Replication – In the above picture,
we have 2 master’s and 1 slave, where, master 1 is master of
master 2, master 2 is master of …
On September 21st, during the opening keynote at MySQL Connect 2013, Tomas Ulin disclosed the release of MySQL 5.7.2. This is a milestone release that includes several new features. Unlike the Previous one, which was just a point of pride, where Oracle was stating its continuous commitment to releasing new versions of MySQL. In MySQL 5.7.2, we see several new features:
- First and foremost, performance. The announcement slides say MySQL 5.7.2 is 95% faster than MySQL 5.6 and 172% faster than MySQL 5.5. I don’t know yet in which circumstances these numbers hold true, but I am sure someone at Percona will soon prove or disprove the claim.
- Performance Schema tables for several aspects:
- …
Many CMS-backed sites are built using MySQL and are launched on cloud infrastructure. In order to mitigate down-time due to regional outages, it is advisable to create a geo-distributed redundancy topology in both the app layer as well as within the database. GenieDB makes it very easy to set up multiple MySQL database servers around the world that are automatically kept synchronized as data is changed on any of the nodes. The database nodes are typically paired 1-on-1 with an app or web server. Some of our customers use the app servers to dish out their CMS backed sites. The database is kept synchronized, but the customers still need to find a way to keep the media content that they use to be available on all these app/web servers. Below is a simple setup that can be easily configured within a very small budget and provides high availability for both the data and the static content during an outage.
While some of our customers use …
[Read more]
On the new milestone release MySQL 5.7.2, we did some
optimizations on binlog lock and dump thread. Major
dump thread code was re-written: Some code never reached was
removed; Complex
logic was simplified; Code became more readable. But I don't want
to introduce the refactoring here. Today, I would like to
introduce you the optimization on binlog lock which improved
master throughput.
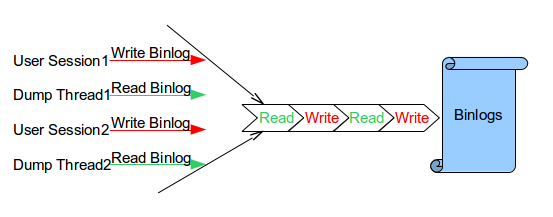
Background binlog lock(LOCK_log) is a mutex which is used to
protect binlog read and write operations. With this mutex, binlog
read and write operations are safe. But it has limited
concurrency. Not only can dump threads and user sessions not read
and write binlog simultaneously but even the dump threads
themselves cannot read the binlog simultaneously. All other sessions have to wait whenever one
session …
{kind=link}
Semi-synchronous replication is used by many users who want
improved data integrity. Today I would like to introduce a
semi-synchronous new feature on MySQL 5.7.2 milestone
release which enhances the data integrity between master and
slave.
Wait Slave Acknowledgement before Engine Commit As you know, with
semi-synchronous replication enabled, user sessions will wait for
acknowledgement from a slave before committing the transaction.
To enhance data integrity, this feature makes transaction
sessions wait a little bit earlier than MySQL 5.5 and MySQL 5.6.
The wait happens just before the server commits to storage
engine.
With this feature, semi-synchronous replication is able to
guarantee:
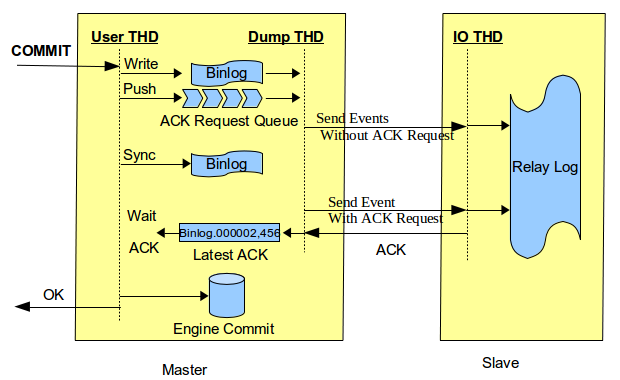{kind=link}
- All committed transaction are already replicated to at least …
Applications should be written taking into account that errors
will eventually happen and, in particular, database application
developers usually consider this while writing their
applications.
Although the concepts required to write such applications are
commonly taught in database courses and to some extent are widely
spread, building a reliable and fault-tolerant database
application is still not an easy task and hides some pitfalls
that we intend to highlight in this post with a set of
suggestions or tips.
In what follows, we consider that the execution flow in a
database application is characterized by two distinct phases:
connection and business logic. In the connection phase, the
application connects to a database, sets up the environment and
passes the control to the business logic phases. In this phase,
it gets inputs from a source, which may be an operator, another
application or a component within the same …