I read Tokyo Cabinet: Beyond Key-Value Store today from one of the news sites, and it reminded me of Brian’s hack on Tokyo Cabinet == Tokyo Engine. Looking at TokyoEngine in Brian’s Mercurial repository, there have been no updates in over a year. Is anyone planning on taking up development of this? Tokyo Cabinet looks really interesting, and Brian has already started the enabling of making it a MySQL engine.
[Read more]
Feb
15
2009
Feb
12
2009
This article accompanies the slides from a presentation on database sharding. Sharding is a technique used for horizontal scaling of databases we are using at Netlog. If you’re interested in high performance, scalability, MySQL, php, caching, partitioning, Sphinx, federation or Netlog, read on …
This presentation was given at the second day of FOSDEM 2009 in Brussels. FOSDEM is an annual conference on open source software with about 5000 hackers. I was invited by Kris Buytaert and Lenz Grimmer to give a talk in the MySQL Dev Room. The talk was based …
[Read more]
Feb
09
2009
Here are the slides from yesterday’s presentation about horizontal database scaling through sharding at the mySQL dev room at FOSDEM 2009.
I’ve got a ton of notes and remarks to these slides, which will become available here soon.
Feb
06
2009
A while back, Ted Ts’o asked for a incremental backup solution that used a database. It reminded me of the talk at the 2009 MySQL Conference & Expo, titled Build your own MySQL time machine.
Chuck and Mats will talk about the backup and replication code, and will show off a web interface, that allows you to go back in time, similar to Apple’s Time Machine in Mac OS X. Its a talk that I most certainly want to attend, as an avid Time Machine user.
Register for the MySQL Conference & Expo 2009 before February 16, and you’ll get an early bird discount (saving $200). April …
[Read more]
Feb
02
2009
Jan
21
2009
A user recently asked: What kind of approaches and techniques can you employ to become familiar with an existing database if you are tasked with supporting and/or modifying it? How can you easily and effectively ramp up your knowledge of a database you have never seen before?Here was my reply:The first thing I do is create an Entity-Relationship Diagram (ERD). Sometimes you can
Jan
21
2009
As a long time DBA and Database Architect this idea is repugnant – make a database 100% de-normalized; one table and except for the one query, retrieval by primary key, nothing else works. And yet we have had great success using this kind of database.
This does not replace the original normalized database, rather it is more like a permeant cache fed from the main database. It is a MySQL database which has certain advantages over Memcached or other true caches such as it is permanent until our processes replace it.
Consider what it might take to build a simple web page: get a request, process it which might take many queries and some significant processing then send back your html.
[Read more]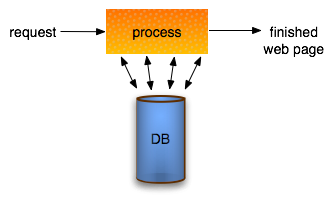{kind=link}
Jan
19
2009
Dear Lazyweb,
So, I’ve been in Chicago for a week teaching a beginner and an intermediate course on using and administering Linux machines. This week, I’ll teach an intermediate and an advanced course on Linux, and the advanced course will cover profiling and debugging. The main tools I’m covering will be valgrind and oprofile, though I’ll be going over lots of other stuff, like iostat, vmstat, strace, what’s under /proc, and some more basic stuff like sending signals and the like.
So what makes me a bit nervous is, being that the advanced students are mostly CS-degree-holding system developers, they’ll probably be expecting me to know very low-level details of how things are implemented at the system/kernel level. I’d love to know more about that myself, and actively try to increase my knowledge in that area! Alas, most of my experience with low-level …
[Read more]
Jan
17
2009
As I’ve written in my previous post “1/3 Implementing an AutoSuggest feature using MySQL fulltext indices”, it’s possible to use the MySQL/MyISAM full-text index to extract search words for an AutoSuggest feature with great performance (because the index tree is used actually). This tool, called myisam_suggest, is my first implementation of this. Download Here: myisam_suggest.c [...]
Jan
17
2009
The MySQL full-text index Current MySQL versions provide a full-text index (FTI) which is generally used to index and search MyISAM (the default storage engine in MySQL) tables like this: SELECT id, content FROM documents WHERE MATCH(content) AGAINST ("tes*" IN BOOLEAN MODE) Internally, every indexed (text) column of a row is splitted into its words. [...]