Table of contents:
- Introduction
- Common reasons for switching the primary node
- Primary Promotion and its importance
- Methods for switching the primary node
- …
There was an idea. An idea to make Vitess self-reliant. An idea to get rid of the friction between Vitess and external fault-detection-and-repair tools. An idea that gave birth to VTOrc… Both VTOrc and Orchestrator are tools for managing MySQL instances. If I were to describe these tools using a metaphor, I would say that they are kinda like the monitor of a class of students. They are responsible for keeping the MySQL instances in check and fixing them up in case they misbehave, just like how a monitor ensures that no mischief happens in the classroom.
Fig 1. Typical management configuration
MySQL Cluster is designed to be a High Availability, Fault Tolerant database where no single failure results in any loss of service.
This is however dependent on how the user chooses to architect the configuration – in terms of which nodes are placed on which physical hosts, and which physical resources each physical host is dependent on (for example if the two blades containing the data nodes making up a particular node group are cooled by the same fan then the failure of that fan could result in the loss of the whole database).
Of course, there’s always the possibility of an entire data center being lost due to earthquake, sabotage etc. and so for a fully available system, you should consider using asynchronous replication to a geographically remote Cluster.
Fig 1. …
[Read more]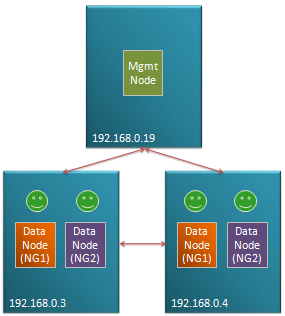{kind=link}