Last weekend I got to present to the MySQL Developers Room at
FOSDEM in Brussels.
The subject of my presentation was NoSQL and SQL the best
of both worlds…
{kind=link}
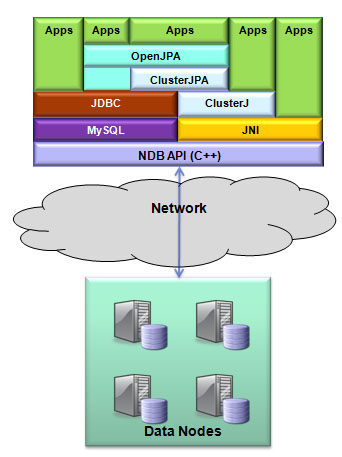
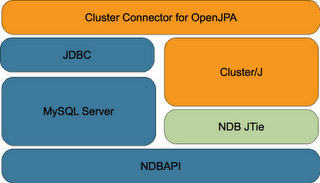
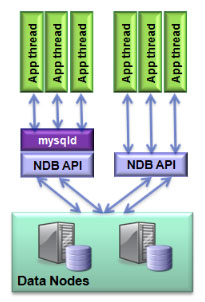
There’s a lot of excitement around NoSQL Data Stores with the promise of simple access patterns, flexible schemas, scalability and High Availability. The downside comes in the form of losing ACID transactions, consistency, flexible queries and data integrity checks. What if you could have the best of both worlds? This session shows how MySQL Cluster provides simultaneous SQL and native NoSQL access to your data – whether a simple key-value API (Memcached), REST, JavaScript, Java or C++. You will hear how the MySQL Cluster architecture delivers in-memory real-time performance, 99.999% availability, on-line maintenance and linear, horizontal scalability …
[Read more]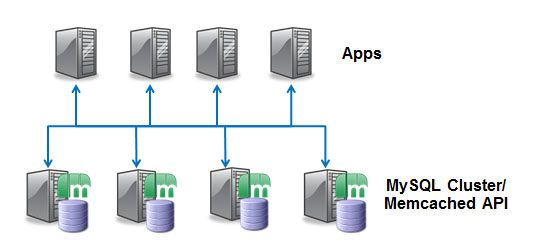{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}