{kind=link}
By default, Cluster will partition based on primary key
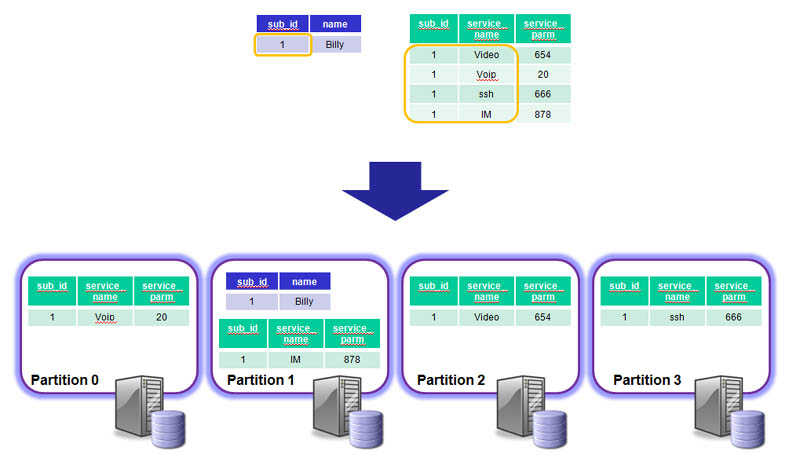
When adding rows to a table that’s using MySQL Cluster as the storage engine, each row is assigned to a partition where that partition is mastered by a particular data node in the Cluster. The best performance comes when all of the data required to satisfy a transaction is held within a single partition so that it can be satisfied within a single data node rather than being bounced back and forth between multiple nodes where extra latency will be introduced.
By default, Cluster partions the data by hashing the primary key. This is not always optimal.
For example, if we have 2 tables, the first using a single-column primary key (sub_id) and the second using a composite key (sub_id, service_name)…
mysql> …[Read more]