Nice article about SimCity outage and ways to defend
databases: http://www.mysqlperformanceblog.com/2013/03/16/simcity-outages-traffic-control-and-thread-pool-for-mysql/
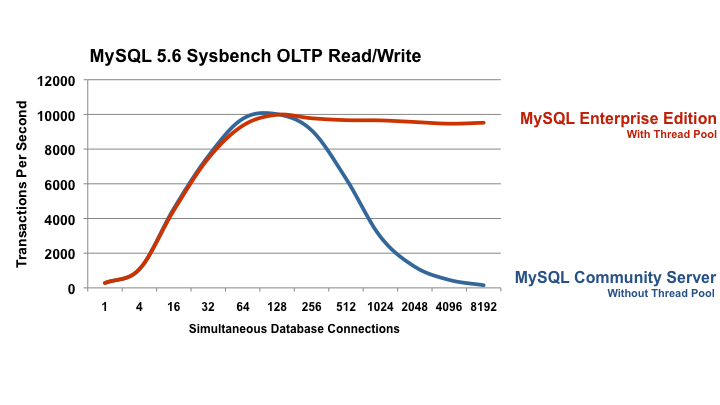
The graphs showing throughput with and without the thread pool
are taken from the benchmark performed by Oracle and taken from
here:
http://www.mysql.com/products/enterprise/scalability.html
The main take away is this graph (all rights reserved to Oracle,
picture original URL):
Scalability is where throughput can grow and grow, as demand
grows. I need to get more from the database, the question …
Apr
03
2013
{kind=link}
Aug
31
2012
Oh I love these things: http://techcrunch.com/2012/08/22/how-big-is-facebooks-data-2-5-billion-pieces-of-content-and-500-terabytes-ingested-every-day/
Every day there are 2.5B content items shares, and 2.7B "Like"s.
I care less about GiGo content itself, but metadata, connections,
relations are kept transactionally in a relational database. The
above 2 use-cases generate 5.2B transactions on the database, and
since there are only 86400 seconds a day, we get over 60000 write
transactions per second on the database, from these 2 use-cases
alone, not to mention all other use-cases, such as new profiles,
emails, queries...
And what's the size of new data, on top of all the existing …
Aug
28
2012
On the 8/16 I conducted a webinar titled: "Scale Up vs. Scale
Out" (http://www.slideshare.net/ScaleBase/scalebase-webinar-816-scaleup-vs-scaleout):
ScaleBase Webinar 8.16: ScaleUp vs.
ScaleOut from ScaleBase
The webinar was successful, we had many attendees and
great participation in questions and
answers throughout the session and in the
end. Only after the webinar it only occurred to me
that one specific graphic was missing from the webinar deck. It
was occurred to me after answering
several audience questions about "the difference
between …
Jul
10
2012
Earlier this week we all read GigaOM's article with this title:
"Why the days are numbered for Hadoop as we know it"I know GigaOM
like to provoke scandals sometimes, we all remember some other
unforgettable piece, but there is something behind
it...
Hadoop today (after SOA not so long ago) is one of the worst case
of an abused buzzword ever known to men. It's everything,
everywhere, can cure illnesses and do "big-data" at the same
time! Wow! Actually Hadoop is a software framework that
supports data-intensive distributed applications, derived from
Google's MapReduce and Google File System (GFS) papers.
My take from the article is this: Hadoop is a foundation,
low-level platform. I used the word …
Jun
28
2012
In a previous post I wrote ARM based servers. Since then,
and thanks to all the comments and responses I got, I looked more
into this ARM thing and it's absolutely fascinating...
Look at this beauty (taken from the site of Calxeda,
the manufacturer):
What is it? A chip? A server? No, it's a cluster of 4
servers...
And this:
is HP Redstone Server, 288 chips, 1,152 cores (Calxeda
quad-core SoC) in a 4U server “Dramatically reducing the cost and
complexity of cabling and …
{kind=link}
{kind=link}
Jun
20
2012
In my previous post I covered the shard-disk paradigm's pros
and cons, but the conclusion that is that it cannot really
qualify as a scale-out solution, when it comes to massive OLTP,
big-data, big-sessions-count and mixture of reads and
writes.
Read/Write splitting is achieved when numerous
replicated database servers are used for reads. This way the
system can scale to cope with increase in concurrent load. This
solution qualifies as a scale-out solution as it
allow expansion beyond the boundaries of one DB, DB
machines are shared-nothing, can be added as a slave to the
replication "group" when required.
And, as a fact, read/write …
{kind=link}
Jun
07
2012
Yesterday I was asked by a customer for the reason why he had
failed to achieve scale with a state-of-the-art "shared-storage"
cluster. "It's a scale-out to 4 servers, but with a shared disk.
And I got, after tons of work and efforts, 130% throughput,
not even close to the expected 400%" he said.
Well, scale-out cannot be achieved with a shared storage and the
word "shared" is the key. Scale-out is done with
absolutely nothing shared or a "shared-nothing"
architecture. This what makes it linear and
unlimited. Any shared resource, creates a tremendous burden
on each and every database server in the cluster.
In a previous post, I identified database engine
activities such as buffer management, locking, thread
locks/semaphores, and recovery tasks - as the main bottleneck in
the OLTP …
May
30
2012
Today, I think we witnessed a small sign for a big
revolution...
http://www.pcworld.com/businesscenter/article/256383/dell_reaches_for_the_cloud_with_new_prototype_arm_server.html
"Dell announced a prototype low-power server with ARM processors,
following a growing demand by Web companies for custom-built
servers that can scale performance while reducing financial
overhead on data centers"In short, ARM (see Wikipedia definition
here) is an architecture standard for processors.
ARM processors are slower compared to good old x86 processors
from Intel and AMD, but have power-efficiency, density and price
attributes that intrigue customers, especially in our days of
green data centers where carbon emissions is …
May
15
2012
In my previous post,http://database-scalability.blogspot.com/2012/05/oltp-vs-analytics.html, I
reviewed the differences between OLTP and Analytics
databases.
Scale challenges are different between those 2 worlds of
databases.
Scale challenges in the Analytics world are with the growing
amounts of data. Most solutions have been leveraging those 3 main
aspects: Columnar storage, RAM and parallelism.
Columnar storage makes scans and data filtering more precise and
focused. After that – it all goes down to the I/O - the faster
the I/O is, the faster the query will finish and bring results.
Faster disks and also SSD can play good role, but above all: RAM! …
{kind=link}
Apr
23
2012
Yesterday (4/19) I attended the AWS Summit in NYC (http://aws.amazon.com/aws-summit-2012/nyc).
I'm a big fan and also a heavy user of AWS especially S3, EC2,
and naturally, RDS. In every point in time I have several dozens
of AWS machines running for me out there in the East region, and
in some cases when we do some special benchmarks and tests,
number of EC2 and RDS machines can easily reach 3-digit. As I
said, I'm a fan...
A few quotes I was able to catch and document on my laptop, on my
laps...:
"When you develop an app for facebook, you must be prepared (and
be afraid) that to your party, not noone will show up, but
everybody will show up!" So true! Simple and true. We all want to
succeed, to have success with our app. We have to think about
scaling from day 1.
"Database was bottleneck for building of sophisticated apps. This
is …