An increasing number of organizations run applications that
depend on MySQL multi-master replication between remote sites.
I have worked on several such implementations recently.
This article summarizes the lessons from those experiences
that seem most useful when deploying multi-master on existing as
well as new applications.
Let's start by defining terms. Multi-master
replication means that applications update the same tables on
different masters, and the changes replicate automatically
between those masters. Remote sites mean that the
masters are separated by a wide area network (WAN), which implies
high average network latency of 100ms or more. WAN network
latency is also characterized by a long
tail, ranging from seconds due to congestion to hours or even
days if a ship runs over the wrong undersea cable.
…
In the latest episode of our “Meet The MySQL Experts” podcast, Mikael Ronstrom, senior MySQL Architect, explains us how the MySQL Thread Pool improves MySQL Scalability.
You can try out the MySQL Thread Pool via our MySQL Enterprise Edition Trial.
And…MySQL being of Nordic origin, Hyvää Vappua/Glada Vappen to all the Finns and Swedes among us!
Enjoy the podcast!
After updating the AVGFree virus definitions, I was surprised to
find that Zend CE (Community Edition) 4.0.6 had a worm in the
JavaServer.exe file. There was greater surprise when
Zend CE 5.3.9 (5.6.0-SP1) also had the same worm.
This is the message identifying the worm (click on it to see a full size image), and you can read about this particular worm on the Mcafee site:
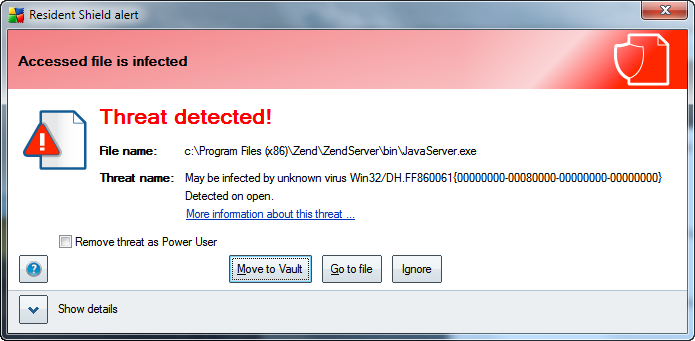{kind=link}
Unless you have the full version of AVG or another security program to try and fix the file, you can only quarantine the file. Quarantine or removal disables Zend CE from working. It begs the questions, “how does Zend release a core file with a worm?”
I’ll update this when there’s a fix to this problem.
New versions of MySQL are always interesting to try out. Often they have features which I may have asked for myself so it’s satisfying to see them eventually appear on a system I use. Often other new features make life easier for the DBA. Finally we hope overall performance will improve and managing the server(s) will be come easier.
So I had a system which needs to make heavy writes, and performance was a problem, even when writing to SSDs. Checkpointing seemed to be the big issue and the ib_logfile size in MySQL 5.5 is limited to 4 GB. That seems a lot, but once MySQL starts to fill these files (and this happens at ~70% of the total I believe), checkpointing kicks in heavily, and slows things down. So the main reason for trying out MySQL 5.6 was to see how things performed with larger ib_logfiles. (Yes, MariaDB 5.5 can do this too.)
Things improved a lot for my specific workload which was great news, but one thing …
[Read more]
We are pleased to announce that MySQL Enterprise Monitor 2.3.10
is now available for download on the My Oracle Support (MOS) web
site as our latest GA release. It will also be available via the
Oracle Software Delivery Cloud in approximately 1-2 weeks. This
is a maintenance release that contains several new features and
fixes a number of bugs. You can find more information on the
contents of this release in the changelog:
http://dev.mysql.com/doc/mysql-monitor/2.3/en/mem-news-2-3-10.html
You will find binaries for the new release on My Oracle
Support:
https://support.oracle.com
Choose the "Patches & Updates" tab, and then use the "Product or
Family (Advanced Search)" feature.
And from the Oracle Software Delivery Cloud …
There are different types of failures in the database environment
ranging from the loss of the network, to the loss of an instance,
all the way to the loss of a node (the server hardware). A robust
database is one that can detect such failures and automate the
failover and recovery process without any user
intervention.SchoonerSQL does exactly that: it detects failures
and provides an immediate and automated failover process. Below
are the failover scenarios and how SchoonerSQL will handle
them.
Instance FailureConsider three instances in a synchronous
replication group where Node 1 has the master instance, and Node
2 and Node 3 have slave instances.The master has one write
virtual IP (10.1.1.2) and one read virtual IP (10.1.1.3); slave
instances have read virtual IPs (10.1.1.4, 10.1.1.5) as shown in
the diagram below.
…
It has been 4 weeks since I last posted the goings-on for Mozilla DBs. April is always a crazy month because of the annual MySQL conference (Some great pics here). This year it was the Percona Live: MySQL Conference and Expo. And of course as soon as I get caught up from the conference, I have to submit more sessions to MySQL Connect (call for papers closes Sunday May 6th) and Percona Live: NYC (anyone know when the call for papers for this will close?).
At the conference, I gave a lightning talk and a tutorial. I have …
[Read more]Why this article?
First of all, because I had fun digging in the code.
Then, I was reading a lot about the improvements we will have in MySQL 5.6 and about some already present in 5.5. Most of them are well covered by people that certainly know more than me, so I read and read, but after a while became curious. I began reading the code and performing tests. I started to compare versions, like 5.1 – 5.5. – 5.6. One of the things I was looking for was how the new Purge thread mechanism works and what were its implications. I have to say that it seems to work better than the previous versions, and the Dimitry blog (see reference) seems to confirm that.
So again, why the article? Because I think there are some traps here and there, and I feel the need to write about them. The worse behavior is with MySQL 5.5. This is because in 5.5 we have an intermediate situation, where the purge is not fully …
[Read more]I've been dealing with MySQL Cluster in one way or another since around 2005 or so (back in the MySQL 4.1 days) but it is still full of "funny" surprises. This post is a collection of different locking related issue i ran into during the previous weeks that i had not been aware of up to now (or simply may have forgotten over time)
== Unique hash indexes lock exclusively ==
This is the one that regular users are most likely to run into: in general row logs in MySQL Cluster distinguish between reads and writes so that writers can block other writers, but not readers and readers from other transactions always see the last committed row value (Cluster currently only supports the READ COMMITTED isolation level). As soon as you have a secondary unique index in addition to a primary key things are different though. Internally a unique index that is not the primary key is implemented as a unique hash index in Cluster (and optionally also …
[Read more]Why this article?
First of all because I was having fun in digging in the code.
Then I was reading a lot about the improvements we will have in MySQL 5.6, and of some already present in 5.5.
Most of them are well cover by people for sure more expert then me, so I read and read, but after a while I start to be also curious, and I start to read the code, and do tests.
I start to do comparison between versions, like 5.1 - 5.5. - 5.6
One of the things I was looking to was how the new Purge thread mechanism works and his implications.
I have to say that it seems working better then the previous versions, and the Dimitry blog (see reference) seems confirm that.
So again why the article? Because I think there are some traps here and there and I feel the need to write about them.
The worse behaviour is when using MySQL 5.5, and this is because in 5.5 we have an intermediate …
[Read more]