Version 8.0.12 added many great new features to MySQL. One of the new features included is the memory instrumentation of the XCom cache, which allows users to view and monitor the memory utilization of the cache by querying Performance Schema (PS).…
Nov
04
2018
Nov
01
2018
MySQL 8.0.13 improves replication lag monitoring by extending the instrumentation for transaction transient errors. These temporary errors, which include lock timeouts caused by client transactions executing concurrently as the slave is replicating, do not stop the applier thread: instead, they cause a transaction to retry.…
Oct
25
2018
Enterprises require high availability for their business-critical applications. Even the smallest unplanned outage or even a planned maintenance operation can cause lost sales, productivity, and erode customer confidence. Additionally, updating and retrieving data needs to be robust to keep up with user demand.
Let’s take a look at how Tungsten Clustering helps enterprises keep their data available and globally scalable, and compare it to Amazon’s RDS running MySQL (RDS/MySQL).
Replicas and Failover What does RDS do?
Having multiple copies of a database is ideal for high availability. RDS/MySQL approaches this with “Multi-AZ” deployments. The term “Multi-AZ” here is a bit confusing, as enabling this simply means a single “failover replica” will be created in a different availability zone from the primary database instance. …
[Read more]
Oct
23
2018
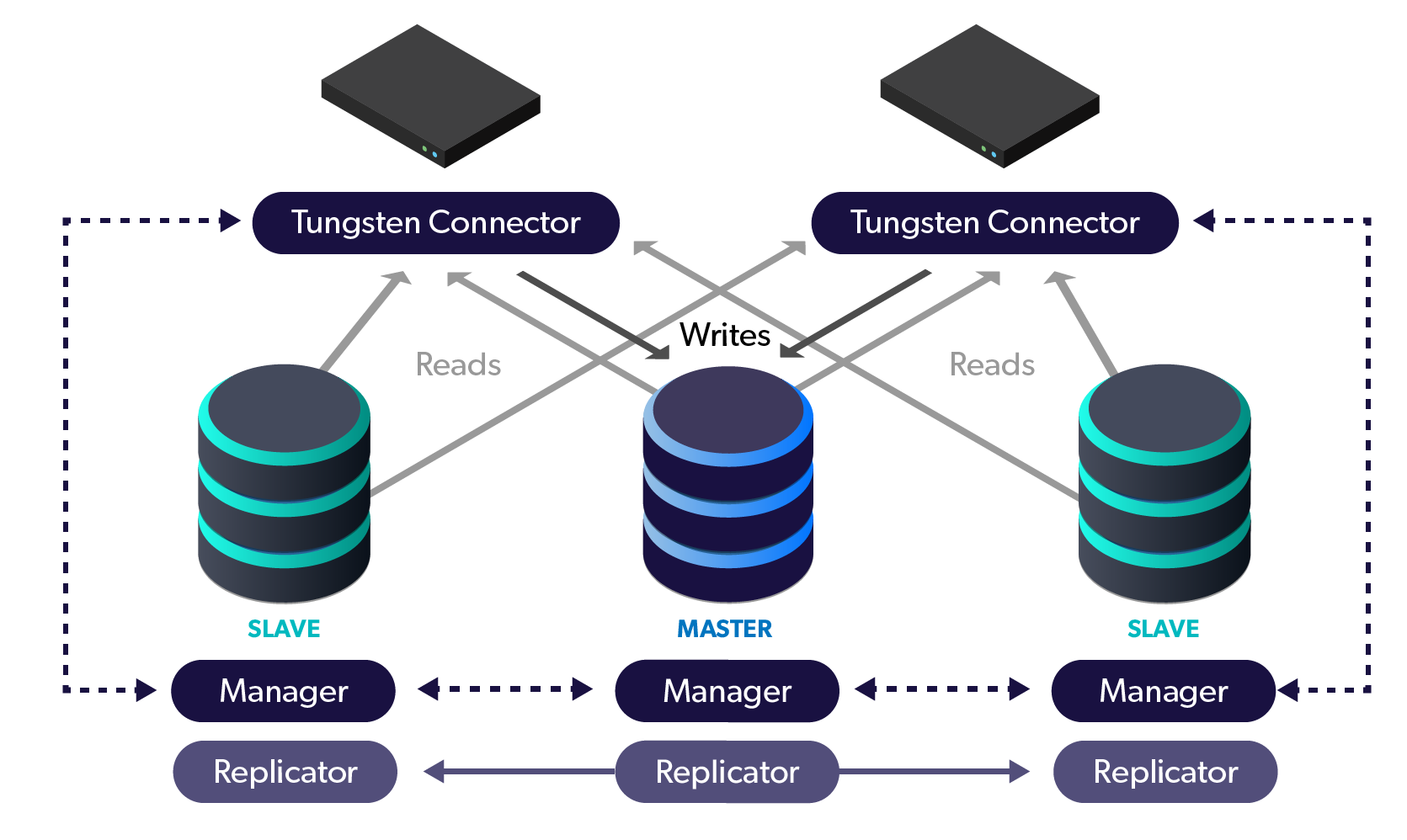
One important way to protect your data is to keep your Tungsten Clustering software up-to-date.
{kind=link}
A standard cluster deployment uses three nodes, which allows for no-downtime upgrades along with the ability to have a fully available cluster during maintenance.
Please note that with only two database cluster nodes, there is a window of vulnerability created by leaving zero failover candidates available when the lone slave is taken down for service.
The Best Practices: Staging Performing a No-Downtime Upgrade for a Staging Deployment
When upgrading a Staging-style deployment, all nodes are upgraded
at once in parallel via the tools/tpm update command
run from inside the staging directory on the staging host.
No Master switch happens, and all layers are restarted to use the new code. …
[Read more]
Oct
23
2018
The MySQL Development Team is very happy to announce the second 8.0 Maintenance Release of InnoDB Cluster!
In addition to bug fixes, 8.0.13 brings some new exciting features:
- Defining the next primary instance “in line”
- Defining the behavior of a server whenever it drops out of the cluster
- Improved command line integration for DevOps type usage
Here are the highlights of this release!…
Oct
18
2018
Tungsten Clustering is an extraordinarily flexible tool, with options at every layer of operation.
In this blog post, we will describe and discuss the two different methods for installing, updating and upgrading Tungsten Clustering software.
When first designing a deployment, the question of installation methodology is answered by inspecting the environment and reviewing the customer’s specific needs.
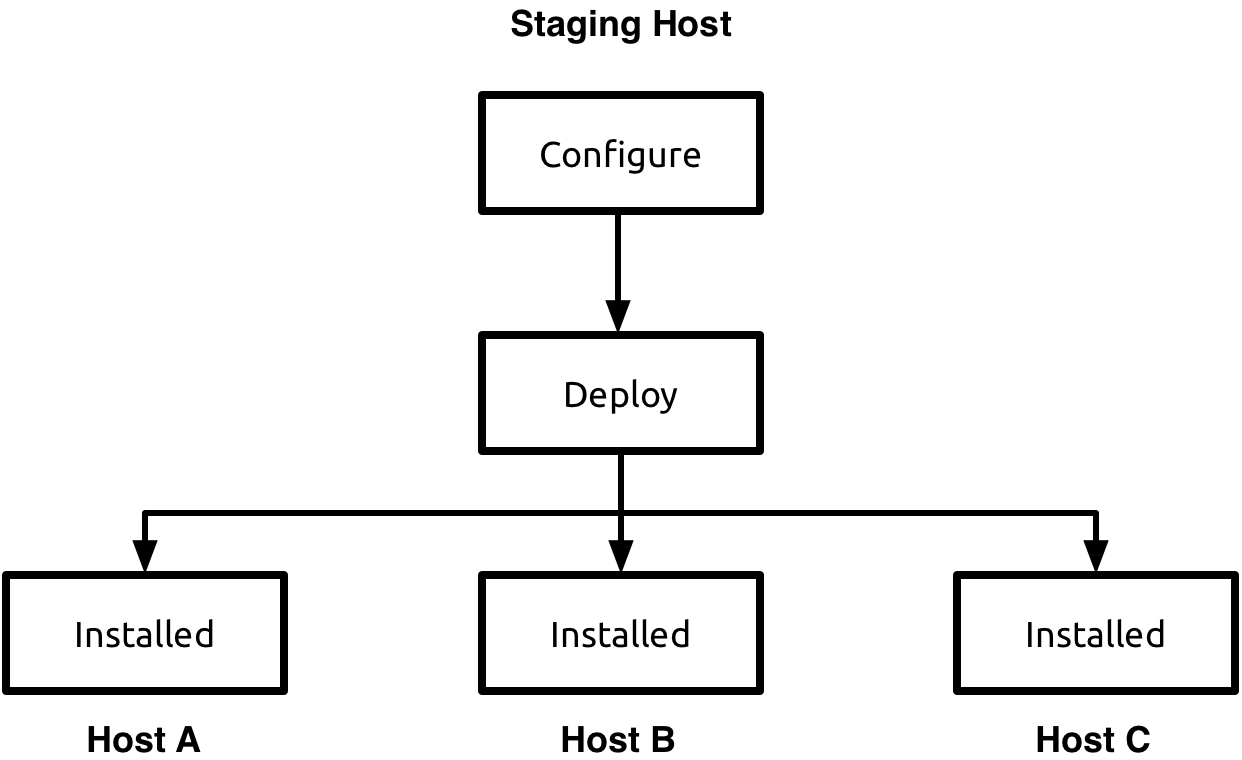
Staging Deployment Methodology
{kind=link}
All for One and One for All
Staging deployments were the original method of installing
Tungsten Clustering, and relied upon command-line tools to
configure and install all cluster nodes at once from a central
location called the staging server.
This staging server (which could be one of the cluster nodes) requires SSH access to all …
[Read more]
Oct
16
2018
Your database cluster contains your most business-critical data and therefore proper performance under load is critical to business health. If response time is slow, customers (and staff) get frustrated and the business suffers a slow-down.
If the database layer is unable to keep up with demand, all applications can and will suffer slow performance as a result.
To prevent this situation, use load tests to determine the throughput as objectively as possible.
In the sample load.pl script below, increase load by
increasing the thread quantity.
You could also run this on a database with data in it without polluting the existing data since new test databases are created to match each node’s hostname for uniqueness.
Note: The examples in this blog post assume that a Connector is …
[Read more]
Oct
11
2018
In a previous post we went into detail about how to implement Tungsten-specific checks. In this post we will focus on the other standard Nagios checks that would help keep your cluster nodes healthy.
Your database cluster contains your most business-critical data. The slave nodes must be online, healthy and in sync with the master in order to be viable failover candidates.
This means keeping a close watch on the health of the databases nodes from many perspectives, from ensuring sufficient disk space to testing that replication traffic is flowing.
A robust monitoring setup is essential for cluster health and viability – if your replicator goes offline and you do not know about it, then that slave becomes effectively useless because it has stale data.
Nagios Checks The Power of Persistence
One …
[Read more]
Oct
09
2018
The MySQL Replication was my first project as a Database
Administrator (DBA) and I have been working with Replication
technologies for last few years and I am indebted to contribute
my little part for development of this technology. MySQL supports
different replication topologies, having better understanding of
basic concepts will help you in building and managing various and
complex topologies. I am writing here, some of the key points to
taken care when you are building MySQL replication. I consider
this post as a starting point for building a high performance and
consistent MySQL servers. Let me start with below key
points Hardware. MySQL Server Version MySQL Server Configuration
Primary Key Storage Engine I will update this post with relevant
points, whenever I get time. I am trying to provide generic
concepts and it will be applicable to all version of MySQL,
however, some of the concepts are new and applicable to latest
versions …
Oct
04
2018
{kind=link}
MySQL Group Replication (GR) is a MySQL Server
plugin that enables you to create elastic, highly-available,
fault-tolerant replication topologies. Groups can operate in
a
single-primary mode with automatic primary election, where only
one server accepts updates at a time. Alternatively, groups can
be deployed in multi-primary mode, where all servers can accept
updates, even if they are issued concurrently.…