As a follow on to my previous post on using Solaris SMF to manage Cluster, I'll
expand my setup and show how to dynamically add data nodes to
Cluster and control the new nodes with SMF.
First, the setup. Since I wanted something that would run
completely on my laptop, I decided to clone my current
OpenSolaris VM (hostname = craigOS_0609) to create a
second "machine" (hostname = craigOS_0609_vm2). Thought
this would be easy and it was, except for the networking piece.
When I just had a single VM, NAT worked fine. However, trying to
use two VMs of OpenSolaris with NAT turned out to be problematic.
They both ended up with a 10.0.2.15 IP address. Researched it a
bit and didn't find anything definitive but did see that bridged
networking might be the way to go. Well, after futzing with it
for a day or so, it turned out …
Scribe is a bit buggy with displaying this presentation:
Scaling a Widget Company
I’ve been following the excellent work that Jan, Kay, and others have been doing with MySQL Proxy, it has really matured into a great piece of software. I talked to Jan at the MySQL UC and toyed with the idea of integrating libdrizzle into MySQL Proxy. I’ve also been asked by a number of folks when a Drizzle Proxy project will be started and if it will be as feature rich as MySQL Proxy. For a while I just said “Someday, I just don’t have the time.” Lately though I am hoping we never have a Drizzle Proxy project.
Let me explain.
One of the fundamental ideas in software engineering is code reuse through libraries or modules. Rather …
[Read more]
I'm pleased to announce the release of DBD::drizzle 0.200. This
release fixes several issues, per Changelog:
* Fixed broken tests
* Fixed bind_type_guessing to work as it does in DBD::mysql
* Added missing insert_id database handle attribute
fetching
* Added several tests that were missing that exist in
DBD::mysql
* Removed extra cruft from lib.pl
* Fixed hash-key retrieval for connection options
* Fixed double-free of imp_dbh->result in dbd_st_destroy
Also worth mentioning is that I've back-ported several fixes that
have been made to DBD::mysql.
I would like to thank everyone who has sent bug reports, patches,
and is using this new driver!
The files:
file:
$CPAN/authors/id/C/CA/CAPTTOFU/DBD-drizzle-0.200.tar.gz
size: 80829 bytes
md5: 9394df460d6d6c70c96cc500dd5a778f
Also:
…
FrOSCon, the Free and Open Source Conference, will take place on August 22nd and 23rd in Sankt Augustin, Germany. Sun Microsystems is a Gold Sponsor of the conference which takes place for the fourth time now. As for the previous years, the organizers have managed to arrange a great lineup of speakers and content. Presentations are held in both English and German — a first draft of the schedule is now available. However, it is still subject to change in some details, based on the feedback by the invited speakers.
I am looking forward to this event, especially since we're helping to organize the OpenSQL Camp subconference there, which will take place in parallel (there also is a subconference about Java this time). By the way: if you've missed the deadline for submitting …
[Read more]It is no joke that computer hardware has advanced by leaps and bounds over the past decade. 10 years ago, multicore systems were expensive and high-end; today, your grandmother may have one and probably have no clue what she has!
Alas, application software has not kept pace. The Linux OS has done a fair job at being able to leverage some of the power multicore systems offer us, but applications running on them have not. The same can be said more or less for Windows, but it’s been a long while since I did anything systems-level with Windows. But the same issues do apply, however.
We are today with the multicore situation where we were in the 80′s and the 90′s with the multithreaded issues. Back then, CPUs grew support for multithreaded programming, but software — including some OSes — were slow to adopt. The Macintosh, when it was first released in 1984, would only support “cooperative” multitasking when the underlying …
[Read more]
I released Spider storage engine version 0.12.(beta)
http://spiderformysql.com/
Spider storage engine can be used for database sharding by using
table partitioning and table link.
Spider storage engine can synchronize an update for remote MySQL
servers by XA transaction at Spider-internal.
Introduction document:
http://www.mysqlconf.com/mysql2009/public/schedule/detail/6837
The main changes in this version are following.
("Table parameter" that is used following is parameters for each
table. Please see "04_table_create.txt" and
"06_table_parameters.txt" in the download documents for more
details.)
- Add table parameter "table_count_mode".
If storage engine can return correct full record
count from table status …
While doing some work for the MySQL MMM
project, I got distracted and browsed around for a bit. I
started searching for MySQL on google code, and then expanded that search into
launchpad, sourceforge and of course forge.mysql.com.
I found that there are literally thousands of FOSS MySQL projects
on these sites. No surprise really, but still not something we
stop to think about every day.
I thought I would share that with you here so you can go and have
a look for yourself to see if you see anything that might be
useful to you. Of course if you do, please blog …
As many people are aware, the best performance can be achieved from MySQL Cluster by using the native (C++) NDB API (rather than using SQL via a MySQL Server). What’s less well known is that you can improve the performance of your NDB-API enabled application even further by ‘batching’. This article attempts to explain why batching helps and how to do it.
What is batching and why does it help?
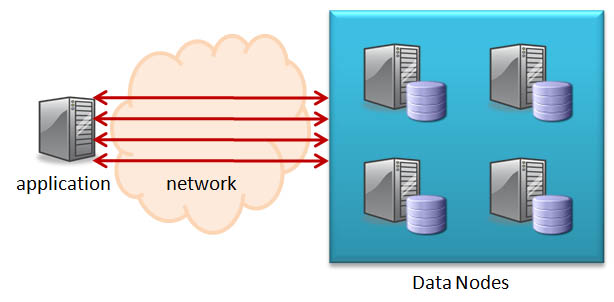{kind=link}
NDB API accessing data from the Cluster without batching
Batching involves sending multiple operations from the application to the Cluster in one group rather than individually; the Cluster then processes these operations and sends back the results. Without batching, each of these operations incurs the latency of crossing the network as well as consuming CPU time on both the application and data node hosts.
By batching …
[Read more]
I found a new crasher in the MySQL 5.0 version which ships with
Ubuntu 6.06 LTS.
> SELECT * FROM (SELECT mu.User FROM mysql.user mu UNION
SELECT mu.user FROM mysql.user mu ORDER BY mu.user) a;
ERROR 2013 (HY000): Lost connection to MySQL server during
query
The bug report: LP392236
On MySQL 5.0.51 on Debian stable it returns this error (like it
should):
ERROR 1054 (42S22): Unknown column 'mu.user' in 'order
clause'
The correct query should be like this (Using culumn a
number):
> SELECT * FROM (SELECT mu.User FROM mysql.user mu UNION
SELECT mu.user FROM mysql.user mu ORDER BY 1) a;