Why does the DIY approach fail to deliver vs. the Tungsten Clustering solution for geo-distributed MySQL multimaster deployments?
Before we dive into the 10 reasons, note why commercially-supported enterprise software is less risky and in fact less costly:
- The labor time spent building and maintaining a DIY solution costs more than a supported solution that just works.
- There is documentation, training, support, so your mission-critical process is never dependent upon an irreplaceable individual.
-
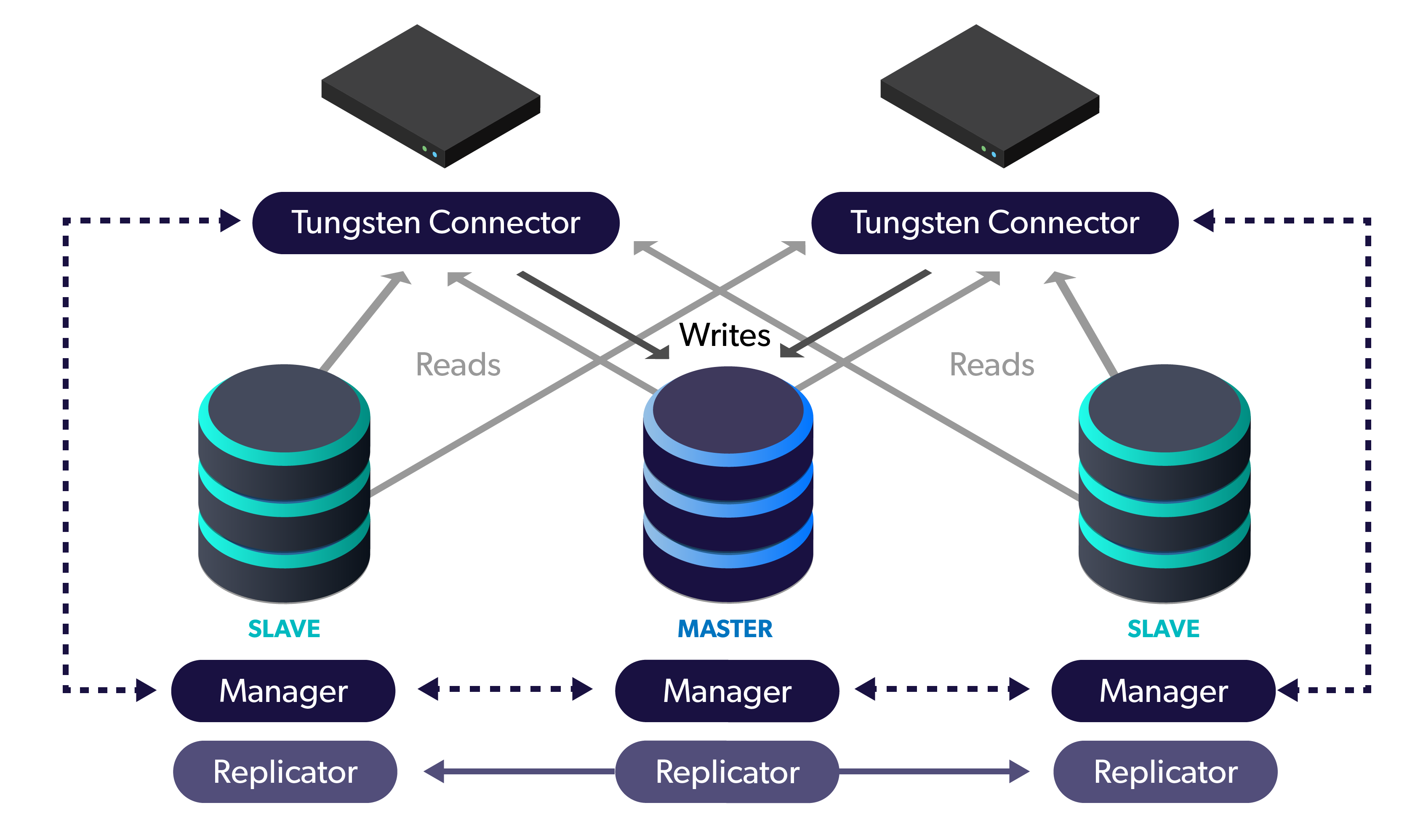
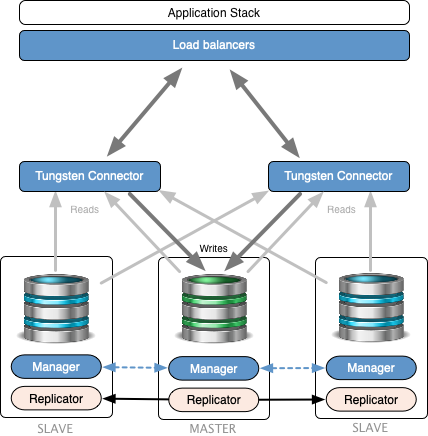
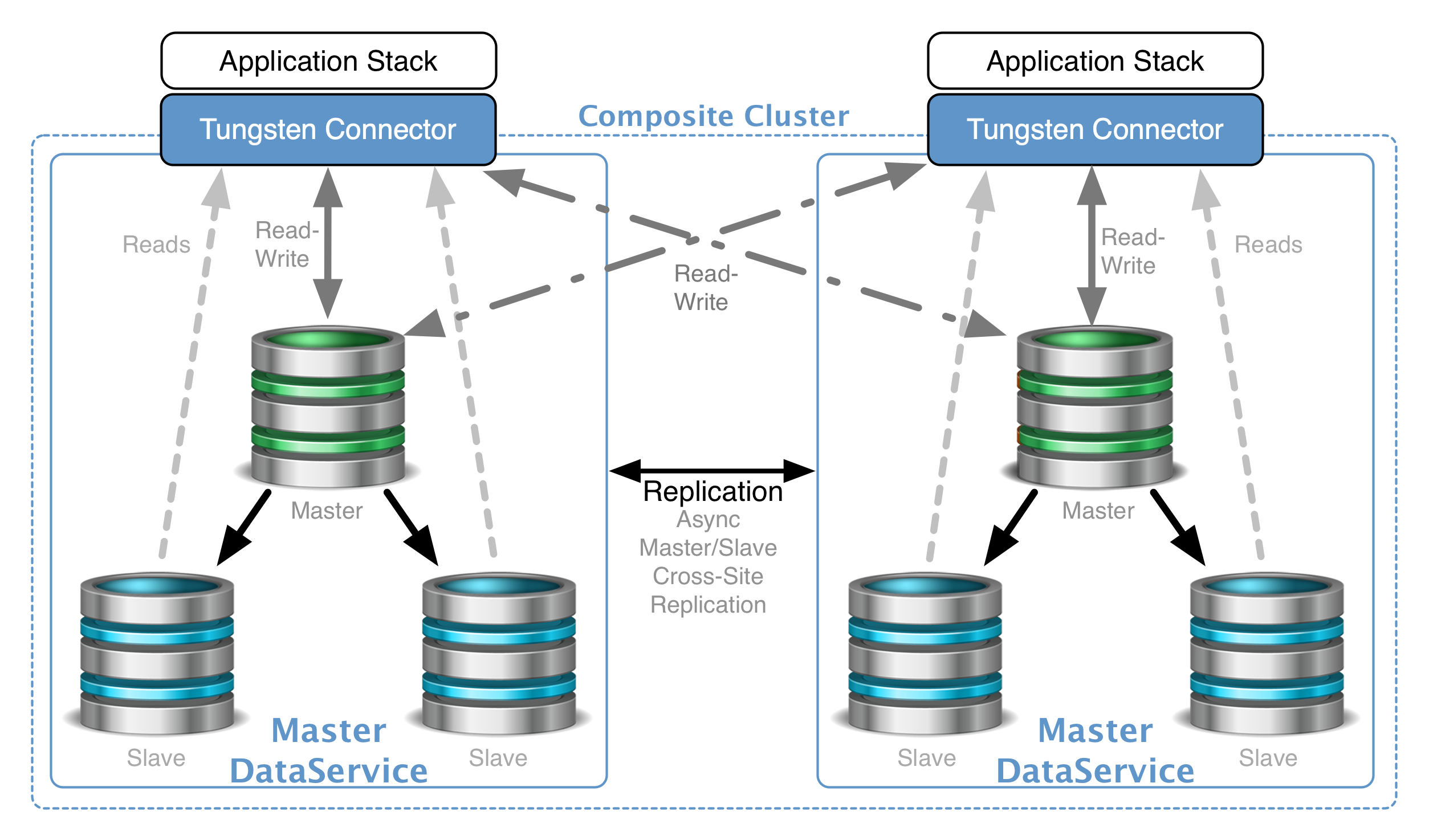
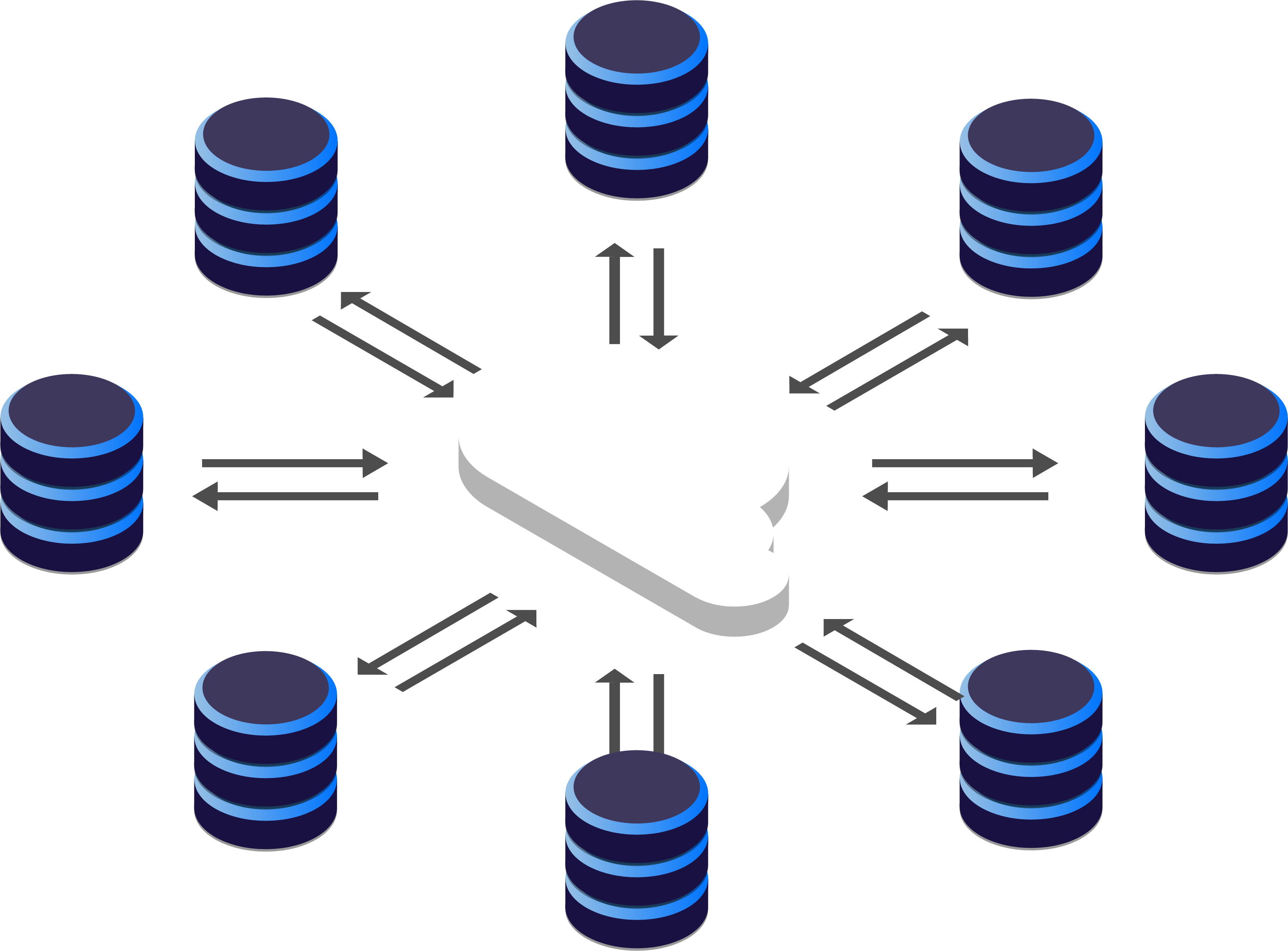
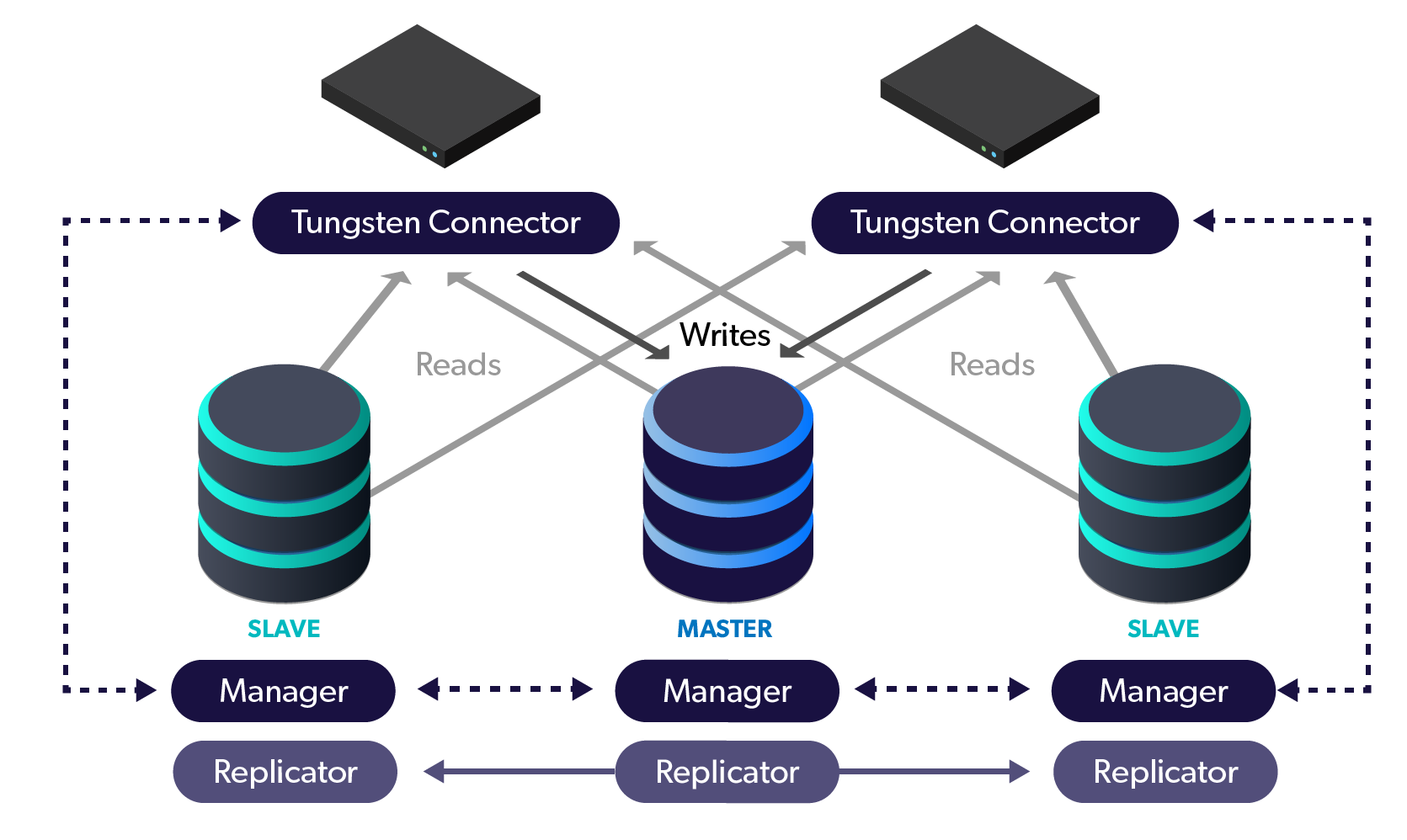
Tungsten Clustering is a complete
solution, comprised of the Replicator, Manager and Connector
components
- With DIY, you must first decide the architecture, then select the individual tools to handle each layer of the topology. …
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}