Real-time analytics allow companies to react rapidly to changing
business conditions. Online ad services process
click-through data to maximize ad impressions. Retailers
analyze sales patterns to identify micro-trends and move
inventory to meet them. The common theme is speed: moving
lots of information without delay from operational systems to
fast data warehouses that can feed reports back to users as
quickly as possible.
Real-time data publishing is a classic example of a big
data replication problem. In this two-part article
I will describe recent work on Tungsten Replicator to move data out of MySQL
into Vertica at high speed with minimal load on
DBMS servers. This feature is known as batch
loading. Batch loading enables not only real-time
analytics but also any other application that depends on moving
data efficiently from MySQL into a data warehouse.
The first article works through the overall solution starting
with replication problems for real-time analytics through a
description of how Tungsten adapts real-time replication to data
warehouses. If you are in a hurry to set up, just skim this
article and jump straight to the implementation details in the
follow-on article.
Replication Challenges for Real-Time Analytics
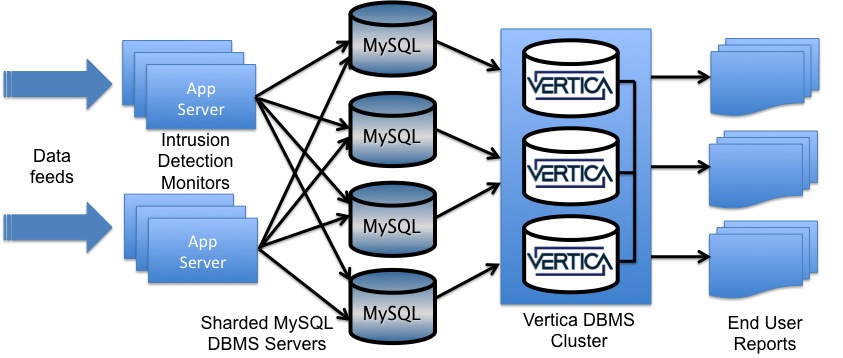
To understand some of the difficulties of replicating to a data
warehouse, imagine a hosted intrusion detection service that
collects access log data from across the web and generates
security alerts as well as threat assessments for users.
The architecture for this application follows a pattern
that is increasingly common in businesses that have to analyze
large quantities of incoming data.
Access log entries arrive through data feeds, whereupon an
application server checks them to look for suspicious activity
and commits results into a front-end DBMS tier of sharded MySQL
servers. The front-end tier optimizes for a MySQL sweet
spot, namely fast processing of a lot of small
transactions.
Next, MySQL data feed as quickly as possible into a Vertica
cluster that generates reports to users. Vertica is a
popular column store with data compression, advanced projections
(essentially materialized views) and built-in redundancy.
(For more on Vertica origins and column stores in
general, read this.) The back-end DBMS tier
optimizes for a Vertica sweet spot, namely fast parallel load and
quick query performance.
There are many challenges in building any system that must scale
to high numbers of transactions. Replicating from MySQL to
Vertica is an especially thorny issue. Here is a short list
of problems to overcome.
{kind=link}
- Intrusion detection generates a lot of data. This type of application can generate aggregate peak rates of 100,000 updates per second into the front-end DBMS tier.
- Data warehouses handle normal SQL commands like INSERT, UPDATE or DELETE very inefficiently. You need to use batch loading methods like the Vertica COPY command rather than submitting individual transactions as they appear in the MySQL binlog.
- Real applications generate not only INSERTS but also UPDATE and DELETE operations. You need to apply these in the correct order during batch loading or the data warehouse will quickly become inconsistent.
- Both DBMS tiers are very busy, and whatever replication technique you use needs to reduce load as much as possible on both sides of the fence.
Until recently there were two obvious options for moving data between MySQL and Vertica.
- Use an ETL tool like Talend to post batches extracted from MySQL to Vertica.
- Write your own scripts to scrape data out of the binlog, process them with a fast scripting language like Perl, and load the result into Vertica.
ETL tools put load on MySQL to scan for changes and often require
application changes, for example to add timestamps to detect
updates. Home grown tools in addition to other limitations
are difficult to maintain and deal poorly with corner cases
unless very carefully tested. Both approaches also add
latency to replication, which detracts from the real-time
delivery goal.
The summary, then, is that there is no simple way to provide
anything like real-time reports to users when large volumes of
data are involved. ETL and home-grown solutions tend to
fall down on real-time transfer as well as the extra load they
impose on already busy servers. That's where Tungsten comes
in.
Developing Tungsten Batch Loading for Data
Warehouses
Our first crack at replicating to data warehouses applied MySQL
transactions to Greenplum using the same approach used for
MySQL--connect with a JDBC driver and apply row changes in binlog
order as fast as possible. It was functionally correct but
not very usable. Like many data warehouses, Greenplum
processes individual SQL statements around 100 times slower than
MySQL. To populate data at a reasonable speed you need to
dump changes to CSV and insert them in batches using gpload, an
extremely fast parallel loader for Greenplum.
We did not add gpload support at that time, because it was
obviously a major effort and we did not understand the
implementation very well. However, I spent the next couple
of months thinking about how to add CSV-based batch loading to
Tungsten. The basic idea was to turn on MySQL row
replication on the master and then apply updates to the data
warehouse as follows:
- Accumulate a large number of transactions as rows in open CSV files.
- Load the files to staging tables.
- Merge the staging table contents into the base tables using SQL.
When a customer showed up needing fast replication into Vertica
from MySQL we were therefore ready to develop batch loading and
dived right in. It looked like a few weeks of work to get
something ready for production deployment, but that estimate
turned out to be quite optimistic. The implementation in
fact took a good bit longer because of the complexities of CSV
formats used by different DBMS services, problems with timezones,
differences in SQL load command semantics, and the fact that when
we started out we did not have an easy-to-setup method to test
heterogeneous replication. Plus we needed to take time to
create a proper installation.
That said, most of the work was SMOP, or a simple matter of
programming. After a few weeks six months we had fast,
functional batch loading for Vertica as well as working
implementations for MySQL and PostgreSQL. Batch loading
applies MySQL row updates in very large groups to Vertica using
CSV files and Vertica COPY commands. The following diagram
shows direct replication using a single pipeline to apply
transactions from a Tungsten master replication to Vertica.
Tungsten replication operates more or less normally up to the
point where we apply to Vertica. This is the job of a new
applier class called SimpleBatchApplier. It implements the
CSV loading as follows.
First, as new transactions arrive Tungsten writes them to CSV
files named after the Vertica tables to which they apply.
For instance, say we have updates for a table simple_tab in
schema test with the following format (slightly truncated from
the vsql \d output):
Schema | Table | Column
| Type |
Size |
--------+------------+-----------------+--------------+------+
test | simple_tab | id
| int |
8 |
test | simple_tab | f_data
| varchar(100) | 100 |
The updates go into file test.simple_tab. Here is an
example of the data in the CSV file.
"64087","I","17","Some data to be inserted","1"
"64088","I","18","Some more data to be inserted","2"
"64088","D","0",null,"3"
The CSV file includes a Tungsten seqno (global transaction ID),
an operation code (I for insert, D for delete), and
the primary key. For inserts, we have additional columns
containing data. Deletes just contain nulls for those
columns. The last column is a row number, which allows us
to order the rows when they are loaded into Vertica.
Tungsten keeps writing transactions until it reaches the block
commit maximum (for example 25,000 transactions). It then
closes each CSV file and loads the contents into a staging table
that has the base name plus a prefix, here "stage_xxx_."
The staging table format mimics the CSV file columns.
For example, the previous example might have a staging
table like the following:
Schema |
Table | Column
| Type | Size |
--------+----------------------+-----------------+--------------+------+
test | stage_xxx_simple_tab | tungsten_seqno |
int | 8 |
test | stage_xxx_simple_tab | tungsten_opcode |
char(1) | 1 |
test | stage_xxx_simple_tab | id
| int
| 8 |
test | stage_xxx_simple_tab | f_data
| varchar(100) | 100 |
test | stage_xxx_simple_tab | tungsten_row_id |
int | 8 |
Finally, Tungsten applies the deletes and inserts to table
test.simple_tab by executing SQL commands like the
following:
DELETE FROM test.simple_tab WHERE id IN
(SELECT id FROM test.stage_xxx_simple_tab
WHERE tungsten_opcode = 'D');
INSERT INTO test.simple_tab(id, f_data)
SELECT id, f_data
FROM test.stage_xxx_simple_tab AS stage_a
WHERE tungsten_opcode='I' AND tungsten_row_id IN
(SELECT MAX(tungsten_row_id)
FROM test.stage_xxx_simple_tab GROUP BY
id);
Simple right? The SQL commands are actually generated from
templates that specify the SQL to execute when connecting to
Vertica, to load a CSV file into the staging table, and to merge
changes from the staging table to the base (i.e., real) table.
You can find the template files in directory
tungsten-replicator/samples/scripts/batch. The template
file format is documented here.
Tungsten MySQL to Vertica replication is currently in field
testing. The performance on the MySQL side is excellent, as
you would expect with asynchronous replication. On the
Vertica side we find that batch loading operates far faster than
using JDBC interfaces. Tungsten has a block commit feature
that allows you to commit very large numbers of transactions at
once. Tests show that Tungsten easily commits around 20,000
transactions per block using CSV files.
We added a specialized batch loader class to perform CSV
uploads to Vertica from other hosts, which further reduces the
load on Vertica servers. (It still needs a small fix to work with Vertica 5 JDBC but
works with Vertica 4.) Taking together the new Vertica
replication features look as if they will be very successful for
implementing real-time analytics. Reading the binlog on
MySQL minimizes master overhead and fetches exactly the rows that
have changed within seconds of being committed. Batch
loading on Vertica takes advantage of parallel load, again
reducing overhead in the reporting tier.
A New Replication Paradigm: Set-Based Apply
Batch loading is significant for reasons other than conveniently
moving data between MySQL and Vertica. Batch loading is
also the beginning of a new model for replication. I would
like to expand on this briefly as it will likely be a theme in
future work on Tungsten.
Up until this time, Tungsten Replicator has followed the
principle of rigorously applying transactions to replicas in
serial order without any deviations whatsoever. If you
INSERT and then UPDATE a row, it always works because Tungsten
applies them to the slave in the same order. This
consistency is one of the reasons for the success of Tungsten
overall, as serialization short-cuts usually end up hitting weird
corner cases and are also hard to test. However, the
serialized apply model is horribly inefficient on data
warehouses, because single SQL statements execute very
slowly.
The SQL-based procedure for updating replicas that we saw in the
previous section is based on a model that I
call set-based apply. It works by treating the
changes in a group of transactions as an ordered
set (actually a relation) consisting of insert and
delete operations. The algorithm is easiest to explain with
an example. The following diagram shows how three row
operation on table t in the MySQL binlog morph to four changes,
of which we actually apply only the last two.
Set-based apply merges the ordered change set to the base table
using the following rules:
{kind=link}
{kind=link}
- Delete any rows from the base table where there is change set DELETE for the primary key and the first operation on that key is not an INSERT. This deletes any rows that previously existed.
- Apply the last INSERT on each key provided it is not followed by a DELETE. This inserts any row that was not later deleted.
This is a form of logical reduction using a combination of
staging tables and CSV loading as described in the previous
section. The rules are implemented as SQL queries.
Taken together these two rules apply changes in a way that
is identical to applying them straight from the binlog.
Using SQL is not the most efficient approach but is
relatively simple to implement and easy for users to
understand.
Set-based apply offers interesting capabilities because sets,
particularly relations, have powerful mathematical properties.
We can use set theory to reason about and develop optimized
handling to solve problems like conflict resolution in
multi-master systems. I will get back to this topic in a
future post.
Meanwhile, there are obvious ways to speed up the apply process
for data warehouses by performing more of the set reduction in
Tungsten and less in SQL. We can also take advantage of
existing Tungsten parallelization capabilities. I predict
that this will offer the same sort of efficiency gains for data
warehouse loading as Tungsten parallel apply provides for I/O-bound
MySQL slaves. Log-based replication is simply a very
good way of handling real-time loading and there are lots of ways
to optimize it provided we follow a sound processing model.
Conclusion
This first article on enabling real-time analytics explained how
Tungsten loads data in real-time from Vertica to MySQL. The
focus has been allowing users to serve up reports quickly from
MySQL-based data, but Tungsten replication obviously applies to
many other problems involving data warehouses.
In the next article I will turn from dry theory to practical
details. We will walk through the details of configuring
MySQL to Vertica replication, so that you can try setting up
real-time data loading yourself.
P.S. If optimized batch loading seems like something you can help
solve, Continuent is hiring. This is just one of a number
of cutting-edge problems we are working on.