As described in the first article of this series, Tungsten
Replicator can replicate data from MySQL to Vertica in real-time.
We use a new batch loading feature that applies
transactions to data warehouses in very large blocks using COPY
or LOAD DATA INFILE commands. This second and concluding
article walks through the details of setting up and testing MySQL
to Vertica replication.
To keep the article reasonably short, I assume that readers are
conversant with MySQL, Tungsten, and Vertica. Basic
replication setup is not hard if you follow all the steps
described here, but of course there are variations in every
setup. For more information on Tungsten check out the
Tungsten Replicator project at code.google.com
site well as current Tungsten commercial documentation at
Continuent.
Now let's get replication up and running!
What Is the Topology?
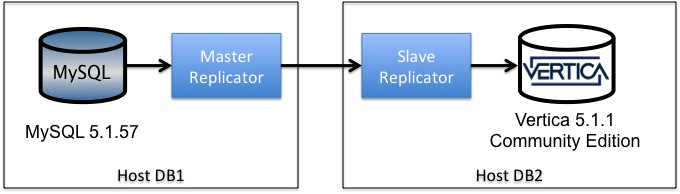
In this exercise we will set up Tungsten master/slave replication
to move data from MySQL 5.1 to Vertical 5.1. Master/slave
is the simplest topology to set up because you don't have to mix
settings for different DBMS types in each service. To keep
keep things simple, we will install Tungsten directly on the
MySQL and Vertica hosts, which are named db1 and db2
respectively. Here is a diagram:
There are of course many other possible configurations. You
can run replicators on separate hosts to reduce load on the DBMS
servers. You can with a little patience set up direct
replication using a Tungsten single replication service, which
results in fewer processes to manage. Finally, you can use
both direct as well as master/slave topologies to publish data
from Tungsten 1.5 clusters. Tungsten clusters provide
availability and scaling on the MySQL side.
Preparing MySQL
To replicate heterogeneously, MySQL servers need to enable
row-based replication. You therefore need to use MySQL 5.1
or higher. Tungsten supports all popular builds of MySQL
5.1 and 5.5, so you can pick your favorite.
Batch replication prints values in CSV files, so setting
mismatches in character sets and timezones between MySQL, the OS
platform, and Vertica will result in corrupted string and/or
dates. Settling on UTF8 charset as server default and
GMT as the default timezone solves these problems. This is
important to get heterogeneous replication to work
properly.
Here are sample my.cnf parameters to enable the recommended
settings.
# Use row replication. binlog-format=row # Server timezone
is GMT. default-time-zone='+00:00' # Tables default to
UTF8. character-set-server=utf8
collation-server=utf8_general_ci
Restart MySQL to pick up new settings. Beyond this you need
to meet the usual requirements for installing Tungsten, such as
defining a 'tungsten' user and ensuring replication is properly
enabled. Check the Tungsten docs for more information.
Preparing Vertica
Next, spin up Vertica. I used Vertica
Community Edition version 5.1.1 for these demos, but any
recent production version should do. There is no special
configuration for the Vertica instance at this point--unlike
MySQL Tungsten works fine with Vertica default settings.
Once Vertica is started and you have created a database, you will
need to login and create a schema to hold Tungsten catalogs.
Here is an example:
$ vsql -Udbadmin -wsecret bigdata Welcome to vsql, the Vertica
Analytic Database v5.1.1-0 interactive terminal.
Type: \h for help with SQL commands
\? for help with vsql commands
\g or terminate with semicolon to execute query
\q to quit
bigdata=> create schema tungsten_mysql2vertica; CREATE
SCHEMA
Note the location of the JDBC driver in your Vertica release
directory. For Vertica 5.1.1 this is located in the
following directory: /opt/vertica/java/lib. It should
have a name like vertica_5.1.1_jdk_5.jar or something
similar.
Downloading and Installing Tungsten
With MySQL and Vertica running, you can now install Tungsten.
Let's first download and unpack the software in a staging
directory. You should do this on the MySQL host as well as
the Vertica host.
db1$ mkdir ~/staging
db1$ cd ~/staging
db1$ wget --no-check-certificate
https://s3.amazonaws.com/files.continuent.com/builds/nightly/tungsten-2.0-snapshots/tungsten-replicator-2.0.6-667.tar.gz
db1$ tar -xf tungsten-replicator-2.0.6-667.tar.gz
db1$ cd tungsten-replicator-2.0.6-667
Note that we use build 667 or later. This is necessary to
pick up recent fixes to ensure compatibility with Vertica Version
5 JDBC drivers. You'll need to download from the Tungsten nightly build page for now.
Now set up the MySQL master. On the MySQL host, run the
following installation command:
db1$ tools/tungsten-installer --master-slave -a \
--service-name=mysql2vertica \
--master-host=db1 \
--cluster-hosts=db1 \
--datasource-user=msandbox \
--datasource-password=msandbox \
--home-directory=/opt/continuent \
--buffer-size=1000 \
--java-file-encoding=UTF8 \
--java-user-timezone=GMT \
--mysql-use-bytes-for-string=false \
--svc-extractor-filters=colnames,pkey \
--property=replicator.filter.pkey.addPkeyToInserts=true
\
--property=replicator.filter.pkey.addColumnsToDeletes=true
\
--start-and-report
This command has some special settings, highlighted in bold, to
help with heterogeneous replication.
{kind=link}
- The Java VM file encoding and timezone are UTF8 and GMT respectively. Standardizing is essential to avoid corrupting data in batch loads.
- String values are translated to UTF8 rather than passed to slaves as bytes.
- We insert filters to add column names and identify the primary key on tables including for INSERT operations. These are both required for batch loading to work correctly.
At the end of a successful master replicator installation you
should see the following message:
INFO >> db1 >> ..... Processing services
command... NAME
VALUE ----
----- appliedLastSeqno: 0 appliedLatency : 0.973 role
: master serviceName
: mysql2vertica serviceType : local
started : true state
: ONLINE Finished services command...
Next, let's turn to the Vertica slave. Before installing
Tungsten on the Vertica host, we must copy in the JDBC driver to
the replicator lib directory. Assuming you are in the
unpacked Tungsten release, you can do this with a command like
the following:
db2$ cp /opt/vertica/java/lib/vertica_5.1.1_jdk_5.jar
tungsten-replicator/lib
Now run the installation command for Vertica, which looks like
the following:
db2$ tools/tungsten-installer --master-slave -a \
--service-name=mysql2vertica \ --cluster-hosts=db2 \
--master-host=db1 \ --datasource-type=vertica
\ --datasource-user=dbadmin \
--datasource-password=secret \ --datasource-port=5433
\ --batch-enabled=true \
--batch-load-template=vertica \
--vertica-dbname=bigdata \ --buffer-size=25000
\ --java-file-encoding=UTF8 \
--java-user-timezone=GMT \
--skip-validation-check=InstallerMasterSlaveCheck \
--start-and-report
Vertica settings are fairly simple. Values that are
different from a standard MySQL configuration are highlighted.
JVM file encoding and timezones should match MySQL.
Note also the very large buffer-size value. This
means that Tungsten can commit up to 25,000 MySQL transactions in
a single block on Vertica. I have tested values up to
100,000 without problems.
If the installation is successful, a message like the following
appears at the end.
INFO >> db2 >> . Processing services command...
NAME VALUE ----
-----
appliedLastSeqno: -1 appliedLatency : -1.0 role
: slave serviceName
: mysql2vertica serviceType : local started
: true state
: ONLINE Finished services command...
Testing MySQL to Vertica Replication
We can check liveness quickly using a heartbeat on the MySQL
master replicator.
db1$ trepctl heartbeat
If everything is working, we then see the following on the
Vertica slave replicator.
db2$ trepctl services Processing services command... NAME
VALUE ----
----- appliedLastSeqno: 1
appliedLatency : 0.266 role
: master serviceName : mysql2vertica
serviceType : local started
: true state : ONLINE
Finished services command...
Next, let's try to replicate something. On MySQL, we need
a table to hold some data, which we create as
follows:
mysql -uroot test ... mysql> create table simple_tab(id int
primary key, f_data varchar(100)) default
charset=utf8;
Now let's create the same table in Vertica, plus a staging table.
We will also have to create a schema 'test' on Vertica as
well.
vsql -Udbadmin -wsecret bigdata Welcome to vsql, the Vertica
Analytic Database v5.1.1-0 interactive terminal.
Type: \h for help with SQL commands
\? for help with vsql commands
\g or terminate with semicolon to execute query
\q to quit
bigdata=> create schema test; CREATE SCHEMA bigdata=>
create table test.simple_tab( bigdata(> id int,
bigdata(> f_data varchar(100) bigdata(> ); CREATE
TABLE bigdata=> bigdata=> create table
test.stage_xxx_simple_tab ( bigdata(> tungsten_seqno
int, bigdata(> tungsten_opcode char(1), bigdata(>
id int, bigdata(> f_data varchar(100),
bigdata(> tungsten_row_id int); CREATE TABLE
Finally, we can try to move a row from one table to the other.
Login to MySQL and insert a row:
mysql> insert into test.simple_tab values(1, 'hello!');
Query OK, 1 row affected (0.00 sec)
If we configured things properly, we will now see the following
on the Vertica side.
bigdata=> select * from test.simple_tab; id |
f_data ----+-------- 1 | hello! (1 row)
At this point our topology is ready to start full-on data
loading.
Troubleshooting
It is common to run into errors when setting up heterogeneous
replication--it's complicated. Don't forget to look at the
replicator logs if 'trepctl status' does not show a meaningful
error message. Here are two of the more common
problems.
- MySQL writes to databases, whereas Vertica has a single database with schemas. If you write to database 'test' in MySQL it goes to schema 'test' on Vertica. It's easy to get confused if you are jumping back and forth.
- Staging tables are easy to mess up. If you get the definition wrong, the Vertica slave will fail. In that case, drop the staging table and recreate it correctly. Then put the replicator back online. We plan to offer an automated tool to create staging tables in the future, but for now it is a little bit painful.
- If you see dates that are off by a couple of hours, you likely did not configure Java timezones correctly. Make sure you have this correctly set. Refer to this for more information.
It is often very useful to look at the CSV files to debug
problems. They are by default located in directory
/tmp/staging/staging0. You can change the CSV file location
in the Tungsten static-svc.properties file that controls the
replication service configuration. Generally speaking, if
there is a problem with loading you just fix it and put the
replicator back online.
If you run into problems that looks like a product issue, feel
free to log a bug. The issue tracking system for
replication is located here. Before logging a bug, though, make
sure it's really a Tungsten problem. Check out Giuseppe
Maxia's hints on proper bug reporting. You can
submit questions on the Tungsten Replicator Discuss group as
well. And if you really get stuck, Continuent offers
commercial support.
Conclusion
This two-part series has provided a short introduction to setting
up MySQL to Vertica replication. You can solve the
real-time analytics problem used as an example in the articles as
well as countless others that require loading data from MySQL to
Vertica.
For more information about the detailed design of Tungsten batch
loading, check out this wiki article. More complete
information will be posted in the Tungsten commercial
documentation at www.continuent.com in the near future.
Meanwhile, enjoy replicating to Vertica and send us
feedback on the Tungsten Replicator Discuss group. I
look forward to hearing about your experiences.