Getting the details just right to fully automate MySQL backups isn't simple. Find out how we accomplished it with our Open Source tool, MyHoard.
May
27
2019
May
27
2019
Getting the details just right to fully automate MySQL backups isn't simple. Find out how we accomplished it with our Open Source tool, MyHoard.
May
25
2019
How to Prepare for MySQL Certification Exam
Here I am
going to suggest MySQL DBA, student or any newbie that how they
can prepare for "Oracle's MySQL 5.x Database Administrator"
certification exam.
Step 1:
Lab
-- Prepare your local MySQL lab environment and make sure to
install the respective MySQL version on your lab. (i.e., if you
are going to appear on MySQL 5.6 DBA exam 1Z0-883 then install MySQL
5.6 on your lab)
-- You can follow my below blog post to create your local MySQL
lab …
{kind=link}
May
25
2019
Install MySQL on CentOS using DBdeployer
1. Here It is assumed You will have a CentOS system/VM. If not,
then please find my this blog post link where you will get
instruction about, how you can create CentOS virtual machine
using the vagrant.
2. Connect to CentOS VM abhinavs-MacBook-Air:centos7-test-vm
agupta$ pwd /Users/agupta/vagrant_box/centos7-test-vm
abhinavs-MacBook-Air:centos7-test-vm agupta$ vagrant
ssh
[vagrant@centos7-test-vm ~]$ sudo su -
[root@centos7-test-vm ~]#
3. Run below command to install the latest …
{kind=link}
May
24
2019
The Question Recently, a customer asked us:
What is the meaning of this error message found in
trepsvc.log?
2019/05/14 01:48:04.973 | mysql02.prod.example.com | [east
- binlog-to-q-0] INFO pipeline.SingleThreadStageTask Performing
rollback of possible partial transaction:
seqno=(unavailable)
Simple Overview The Skinny
This message is an indication that we are dropping any uncommitted or incomplete data read from the MySQL binary logs due to a pending error.
The Answer Safety First
This error is often seen before another error and is an
indication that we are rolling back anything uncommitted, for
safety. On a master this is normally very little and would likely
be internal transactions in the trep_commit_seqno
table, for example.
As you may know with the replicator we always extract complete transactions, and so this particular message is …
[Read more]
May
24
2019
This is a CRITICAL update and the fix mitigates the issues described in CVE-2019-12301. If you upgraded packages on Debian/Ubuntu to 5.6.44-85.0-1, please upgrade to 5.6.44-85.0-2 or later and reset all MySQL root passwords.
Issue
On 2019-05-18 Percona discovered an issue with the Debian/Ubuntu 5.6.44-85.0-1 packages for Percona Server for MySQL. When the previous versions, upgraded to the new version PS 5.6.44-85.0-1 on deb based systems, the MySQL root password was removed allowing users to login to the upgraded server as MySQL root without specifying a password.
Scope
This issue is limited to users who upgraded with the Debian/Ubuntu package 5.6.44-85.0-1 for Percona Server for MySQL v. 5.6. Newer versions (v. 5.7 and above) and new …
[Read more]
May
23
2019
Database migrations don’t scale well. Typically you need to perform a great deal of tests before you can pull the trigger and switch from old to new. Migrations are usually done manually, as most of the process does not lend itself to automation. But that doesn’t mean there is no room for automation in the migration process. Imagine setting up a number of nodes with new software, provisioning them with data and configuring replication between old and new environments by hand. This takes days. Automation can be very useful when setting up a new environment and provisioning it with data. In this blog post, we will take a look at a very simple migration - from standalone Percona Server 5.7 to a 3-node Percona XtraDB Cluster 5.7. We will use Ansible to accomplish that.
Environment Description
First of all, one important disclaimer - what we are going to show here is only a draft of what you might like to run in production. It does …
[Read more]
May
23
2019
I recently stumbled upon a very interesting post by Lukas Eder, where he describes 10 query transformations which do not depend on the database’s cost model. He posted it a couple of years ago, though when I read it, I assumed some portions of it may still be relevant today.
In the original post, several databases were tested to see if their internal optimizer will be able to automatically re-write the SQL queries and optimize them. In those tests, MySQL under-performed in several of the use cases (the tested version was MySQL 8.0.2, which was released on 2017-07-17).
Seeing those results, and given the previous evaluation was done almost two years ago, I thought that now can be a good chance to re-evaluate a few of those tests with the latest MySQL 8.0.16 (released on 2019-04-25), and demonstrate …
[Read more]
May
22
2019
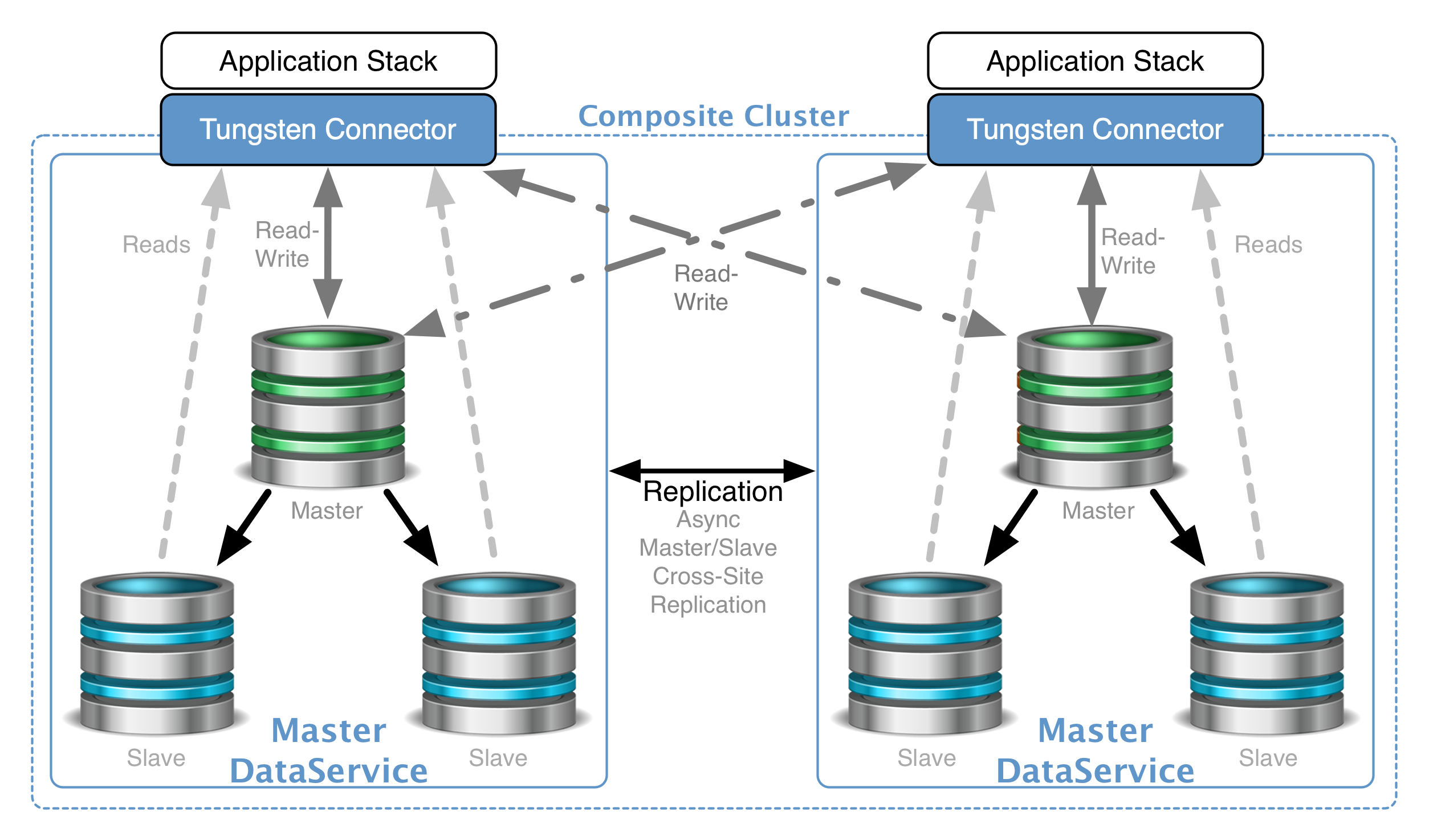{kind=link}
Overview The Skinny
In this blog post we will discuss how the managed cross-site replication streams work in a Composite Multi-Master Tungsten Cluster for MySQL, MariaDB and Percona Server.
Agenda What’s Here?
- Briefly explore how managed cross-site replication works in a Tungsten Composite Multi-Master Cluster
- Describe the reasons why the default design was chosen
- Explain the pros and cons of changing the configuration
- Examine how to change the configuration of the managed cross-site replicators
Cross-Site Replication A Very Brief Summary
In a standard Composite Multi-Master (CMM) deployment, the managed cross-site replicators pull Transaction History Logs (THL) from every remote cluster’s current master node. …
[Read more]
May
22
2019
Feeling the FOMO? Now you don’t have to! With the Percona Live Open Source Database Conference 2019 Live Stream, you’ll practically be there in person, living the experience to the fullest. Our keynote stage features morning and lunchtime keynotes on Wednesday, May 29th and morning keynotes on Thursday, May 30th. Join us at home or on the go, from any corner of the world!
Percona is streaming the keynotes on Wednesday, May 29, 2019, at 9 AM CDT, Wednesday, May 29, 2019, at 1:25 PM CDT, and Thursday, May 30, 2019, at 9 AM, beginning at 9 AM CDT.
Keynote speakers include Continuent, VividCortex, AWS, Facebook, MariaDB Foundation, and many more. The keynote panel will feature topics such as the changing face of Open Source.
The list of keynote talks and speakers for each day is as follows:
…
[Read more]