{kind=link}
Overview
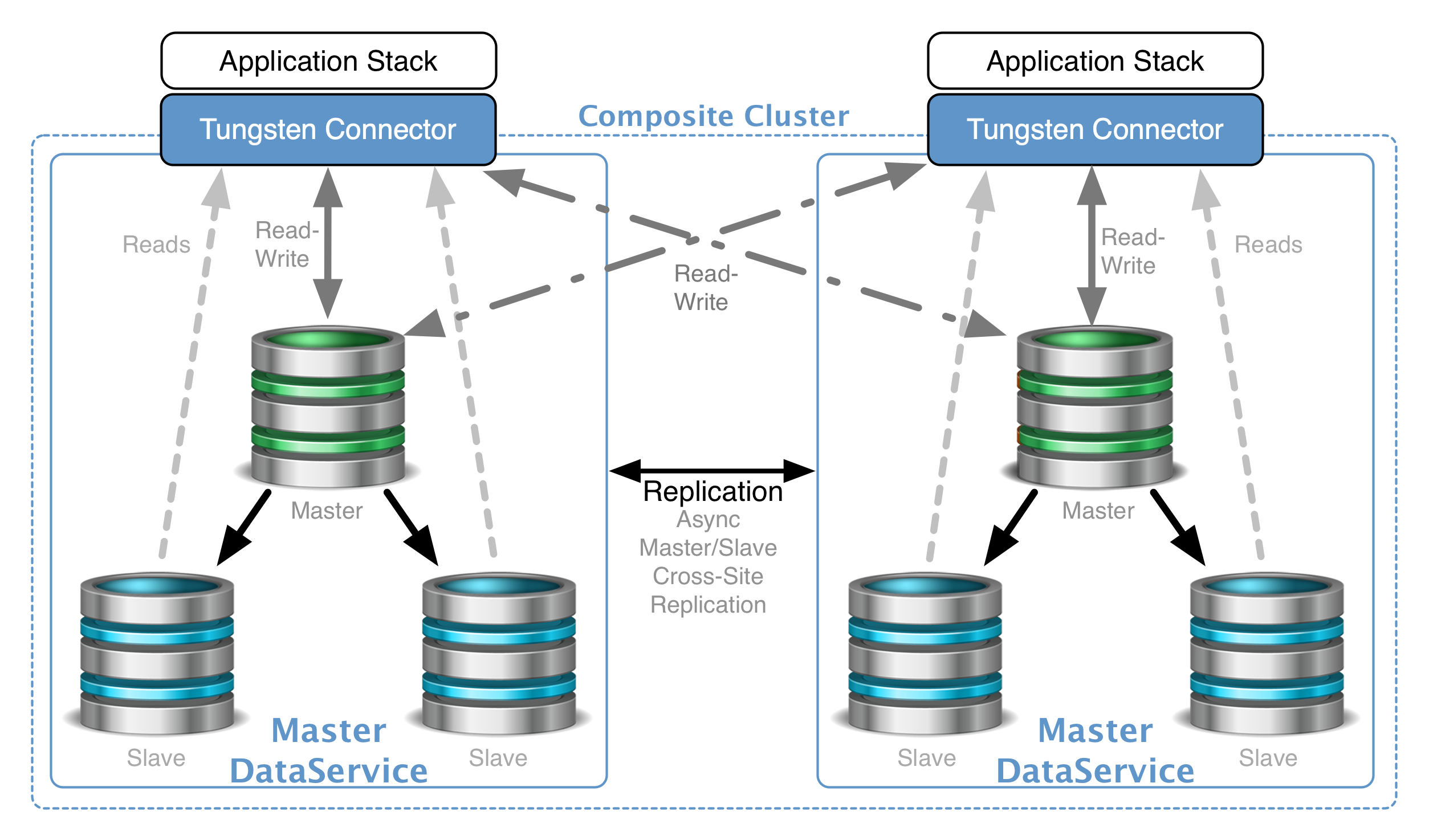
Clustering provides high availability and disaster recovery, along with the ability to read-scale both locally and globally. Some clusters even provide active/active capabilities, which others have a single master.
Real time database replication is a must for clustering and other key business purposes, like reporting. There are a number of replication technologies available for MySQL, and some are even bundled into various solutions. When choosing a replication methodology, it is paramount to understand just how the data moves from source to target. In this blog post, we will examine how asynchronous, synchronous, and “semi-synchronous” replication behave when used for clustering. Also, we will explore how …
[Read more]