By far, the most popular way for PDI users to load data into LucidDB is to use the PDI Streaming Loader. The streaming loader is a native PDI step that:
- Enables high performance loading, directly over the network without the need for intermediate IO and shipping of data files.
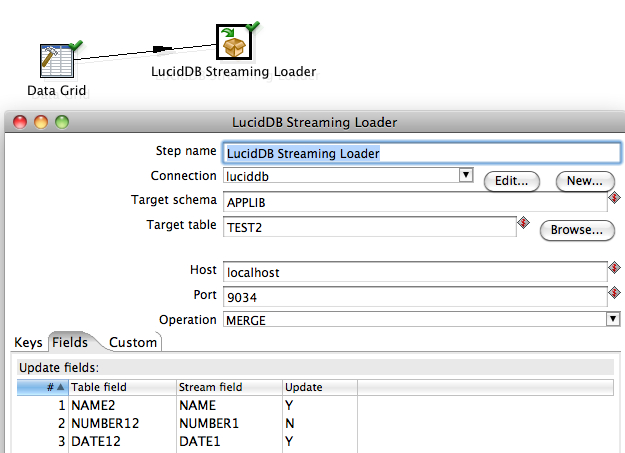
- Lets users choose more interesting (from a DW perspective) loading type into tables. In particular, in addition to simple INSERTs it allows for MERGE (aka UPSERT) and also UPDATE. All done, in the same, bulk loader.
- Enables the metadata for the load to be managed, scheduled, and run in PDI.
{kind=link}
However, we’ve had some known issues. In fact, until PDI 4.2 GA and LucidDB 0.9.4 GA it’s pretty problematic unless you run through the process of patching LucidDB outlined on this page: …
[Read more]