As network use grows and services become more dynamic, so existing Authentication, Authorization and Accounting (AAA) environments can struggle to keep pace with demand.
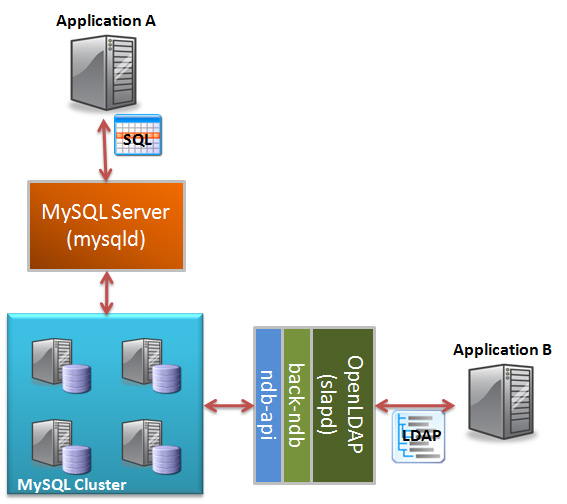
Tune into this webinar where you can hear from the Alan Dekok, one of the founders of the FreeRADIUS project and CEO of Network RADIUS, discuss the concepts and implementation of RADIUS services using the FreeRADIUS server and the MySQL Cluster database to deliver highly available and scalable AAA services.
As always, this webinar is free and you can register here. I will be manning the Q&A during the webinar.
In this session, you will learn about:
- potential AAA limitations as network environments grow
- advantages of deploying FreeRADIUS with MySQL Cluster
- Performance, sizing and deployment of an AAA environment using …
{kind=link}