MySQL replication enables data to be
replicated from one MySQL database server (the master) to one or
more MySQL database servers (the slaves). However, imagine the
number of use cases being served if the slave (to which data is
replicated) isn't restricted to be a MySQL server; but it can be
any other database server or platform with replication events
applied in real-time!
This is what the new Hadoop Applier empowers you to
do.
An example of such a slave could be a data warehouse system such
as Apache
Hive, which uses HDFS as a data store. If you have a Hive
metastore associated with HDFS(Hadoop Distributed File System), the Hadoop
Applier can populate Hive tables in real time. Data is …
Apr
22
2013
Apr
22
2013
This is a follow up post, describing the implementation details
of Hadoop Applier, and steps to configure and install it.
Hadoop Applier integrates MySQL with Hadoop providing the
real-time replication of INSERTs to HDFS, and hence can be
consumed by the data stores working on top of Hadoop. You can
know more about the design rationale and per-requisites in the
previous post.
Design and Implementation:
Hadoop Applier replicates rows inserted into a table in MySQL to
the Hadoop Distributed File System(HDFS). It uses an API provided by libhdfs,
a C library to manipulate files in HDFS.
The library comes pre-compiled with Hadoop distributions. It
connects to the MySQL master (or read …
Apr
22
2013
Every few months, I get the fun job of announcing what’s new in TokuDB®, but this time is special. With Version 7, TokuDB for MySQL and MariaDB is going open source.
The free Community Edition is fully functional and fully performant. It has all the compression you’ve come to expect from TokuDB. It has hot schema changes: no-down-time column insertion, deletion, renaming, etc., as well as index creation. It has clustering secondary keys. We are also announcing an Enterprise Edition (coming soon) with additional benefits, such as a support package and advanced backup and recovery tools.
Making TokuDB open source is a natural next step for Tokutek’s involvement in the MySQL community. So far, Tokutek has been involved in the community in many ways:
- We’ve contributed a number of …
Apr
09
2013
If T.S. Eliot were a MySQL DBA, I think he would have been more upbeat about April.
We are gearing up for an incredible second half of April. We will be presenting three separate sessions at the Percona Live: MySQL Conference and Expo 2013, April 22-25, in Santa Clara, CA. In addition, we will be presenting at SkySQL’s MySQL & Cloud Database Solutions Day on Friday, April 26 at the same location.
Come by to see us in Booth #114, or stop by one of our sessions:
Using TokuDB: A Guided Walk Through a …
[Read more]
Apr
03
2013
Nice article about SimCity outage and ways to defend
databases: http://www.mysqlperformanceblog.com/2013/03/16/simcity-outages-traffic-control-and-thread-pool-for-mysql/
The graphs showing throughput with and without the thread pool
are taken from the benchmark performed by Oracle and taken from
here:
http://www.mysql.com/products/enterprise/scalability.html
The main take away is this graph (all rights reserved to Oracle,
picture original URL):
Scalability is where throughput can grow and grow, as demand
grows. I need to get more from the database, the question …
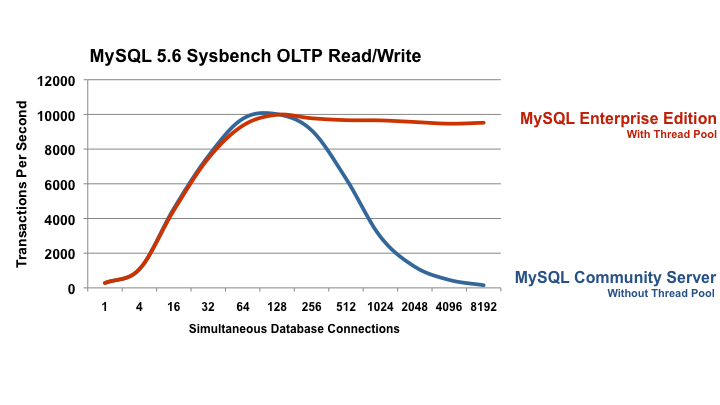{kind=link}
Apr
03
2013
A little while ago I blogged about (and open sourced) an Impala-powered soccer visualization demo, designed to demonstrate just how responsive Impala queries can be. Since not everyone has the time or resources to run the project themselves, we’ve decided to host it ourselves on an EC2 instance. You can try the visualization; we’ve also opened up the Impala web interface, where you can see query profiles and performance numbers, and Hue (username and password are both ‘test’), where you can run your own queries on the dataset.
Deploying Impala on EC2
While there are …
[Read more]
Mar
26
2013
This is a good read, claiming: "Relational Databases Aren't
Dead. Heck, They're Not Even Sleeping", http://readwrite.com/2013/03/26/relational-databases-far-from-dead.
A key quote:
"While not comprehensive, the uses for NoSQL databases center
around the acquisition of fast-growing data or data that does not
easily fit within uniform structures."
There were 2 parts in the statement about NoSQL's uses. I'll
start with the latter:
"data that does not easily fit within uniform structures"
- NoSQL is probably the right choice, hmm although I always
encourage thinking and architecting in advance. And also online
structure changes do exist in the RDBMS world and recently in
MySQL: …
Mar
25
2013
“Working with empirical genomic data and modern computational models, the laboratory addresses questions relevant to how genetics and the environment influence the frequency and severity of diseases in human populations” –Thibault de Malliard. Big Data for Genomic Sequencing. On this subject, I have interviewed Thibault de Malliard, researcher at the University of Montreal’s Philip Awadalla [...]
Mar
11
2013
During the second half of our CUBE discussion with Wikibon analyst Jeff Kelly at this year’s Strata Conference in Santa Clara, we talked about the tipping point for Big Data. Strata veterans could see at a glance that this year’s conference was markedly different. No longer the exclusive domain of geeks and database administrators, this year’s Strata featured some of the biggest enterprise vendors around. With heavy weight enterprise players Intel and EMC Greenplum announcing their own Hadoop distributions, big data is clearly going mainstream. Now that we know how to capture, store, access and analyze big data, what’s the next step? Listen in to hear my conversation with Jeff Kelly about taking big data down its last mile and finally putting it in the hands of business users.
Source: …
[Read more]
Mar
07
2013
We had the opportunity to do a CUBE interview with Wikibon analyst Jeff Kelly at last week’s Strata Conference in Santa Clara. In the first part of our conversation, we discuss how our success in integrating Tokutek’s Fractal Tree® technology into MySQL has led us to another popular database, MongoDB. We explain the results of our recent benchmarking tests with MongoDB, which indicate that adding indexing can also improve performance for this popular NoSQL database with faster insertion rates, lower query latency and greater …
[Read more]