有时候,我们希望将 MySQL 的 relay log 多保留一段时间,比如用于高可用切换后的数据补齐,于是就会设置 relay_log_purge=0,禁止 SQL 线程在执行完一个 relay log 后自动将其删除。但是在官方文档关于这个设置有这么一句话:
Disabling purging of relay logs when using the --relay-log-recovery option risks data consistency and is therefore not crash-safe.
究竟是什么样的风险呢?查找了一番后,基本上明白了原因。
首先,为了让从库是 crash safe 的,必须设置 relay_log_recovery=1,这个选项的作用是,在 MySQL 崩溃或人工重启后,由于 IO 线程无法保证记录的从主库读取的 binlog 位置的正确性,因此,就不管 master_info 中记录的位置,而是根据 relay_log_info 中记录的已执行的 binlog 位置从主库下载,并让 SQL …
[获取更多]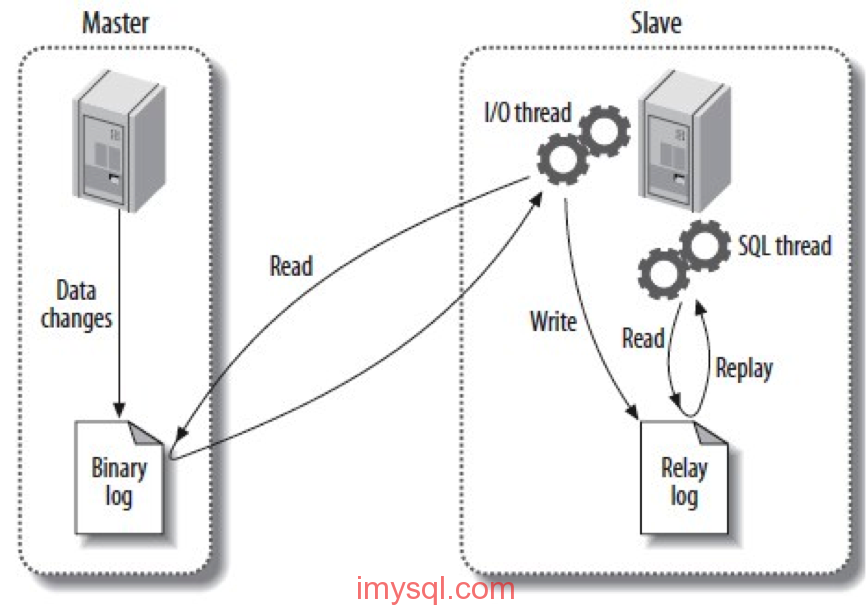{kind=link}