{kind=link}
70x faster joins with AQL
The new GA MySQL Cluster 7.2 Release (7.2.4) just announced by Oracle includes 2 new features which when combined can improve the performance of joins by a factor of 70x (or even higher). The first enhancement is that MySQL Cluster now provides the MySQL Server with better information on the available indexes which allows the MySQL optimizer to automatically produce better query execution plans. Previously it was up to the user to manually provide hints to the optimizer. The second new feature is Adaptive Query Localization which allows the work of the join to be distributed across the data nodes (local to the data it’s working with) rather than up in the MySQL Server; this allows more computing power to be applied to calculating the join as well as dramatically reducing the number of messages being passed around the system. The combined result is that your joins can now run MUCH faster and this post describes a test that results in a 70x speed-up for a real-world query.
{kind=link}
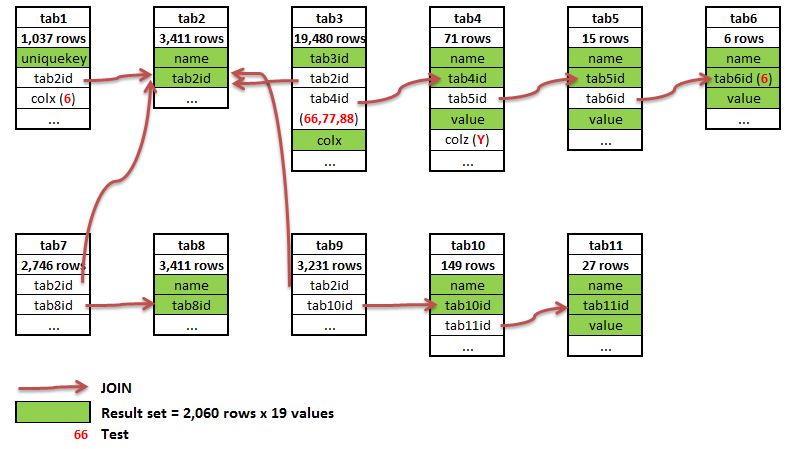
11-Way Join used in Test
The join used in this test is based on a real-world example used for an on-line store/Content Management System. The original query identified all of the media in the system which was appropriate to a particular device and for which a user is entitled to access. As this query is part of a customer’s application I’ve replaced all of the table and column names.
The join runs across 11 tables (which contain 33.5K rows in total) and produces a result set of 2,060 rows, each with 19 columns. The figure to the right illustrates the join and the full join is included below.
SELECT
tab1.uniquekey,
tab8.name,
tab8.tab8id,
tab11.name,
tab11.tab11id,
tab11.value,
tab10.tab10id,
tab10.name,
tab2.name,
tab2.tab2id,
tab4.value + tab5.value + tab6.value,
tab3.colx,
tab3.tab3id,
tab4.tab4id,
tab4.name,
tab5.tab5id,
tab5.name,
tab6.tab6id,
tab6.name
FROM
tab1,tab2,tab3,tab4,tab5,tab6,tab7,tab8,tab9,tab10,tab11
WHERE
tab7.tab2id = tab2.tab2id AND
tab7.tab8id = tab8.tab8id AND
tab9.tab2id = tab2.tab2id AND
tab9.tab10id = tab10.tab10id AND
tab10.tab11id = tab11.tab11id AND
tab3.tab2id = tab2.tab2id AND
tab3.tab4id = tab4.tab4id AND
tab4.tab5id = tab5.tab5id AND
tab4.colz = 'Y' AND
tab5.tab6id = tab6.tab6id AND
tab6.tab6id IN (6) AND
(tab3.tab4id IN (66, 77, 88)) AND
tab1.tab2id = tab2.tab2id AND
tab1.colx = 6;
Enabling AQL
First of all, make sure that you’re using the GA version of MySQL Cluster (7.2.4 or later); the Open Source version is available from http://dev.mysql.com/downloads/cluster/#downloads
and the commercial version from the Oracle Software Delivery Cloud. You can double check that AQL is enabled:
mysql> show variables like 'ndb_join_pushdown'; | ndb_join_pushdown | ON |
{kind=link}
Test configuration
To get the full benefit from AQL, you should run “ANALYZE TABLE;” once for each of the tables (no need to repeat for every query and it only needs running on one MySQL Server in the Cluster). This is very important and you should start doing this as a matter of course when you create or modify a table.
For this test, 3 machines were used:
- Intel Core 2 Quad Core @2.83 GHz; 8 Gbytes RAM; single, multi-threaded data node (ndbmtd)
- Intel Core 2 Quad Core @2.83 GHz; 8 Gbytes RAM; single, multi-threaded data node (ndbmtd)
- 4 Core Fedora VM running on VirtualBox on Windows 7, single MySQL Server
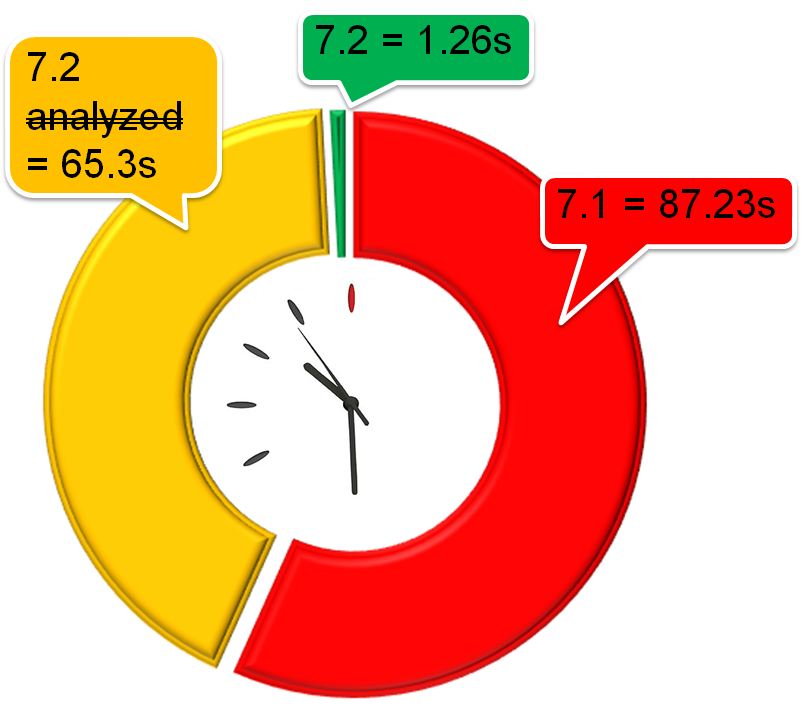
The query was then run and compared to MySQL CLuster 7.1.15a:
| MySQL Cluster 7.1.15a | 1 minute 27.23 secs | |
| MySQL Cluster 7.2.1 (without having run ANALYZE TABLE) | 1 minute 5.3 secs | 1.33x Cluster 7.1 |
| MySQL Cluster 7.2.1 (having run ANALYZE TABLE) | 1.26 secs | 69.23x Cluster 7.1 |
{kind=link}
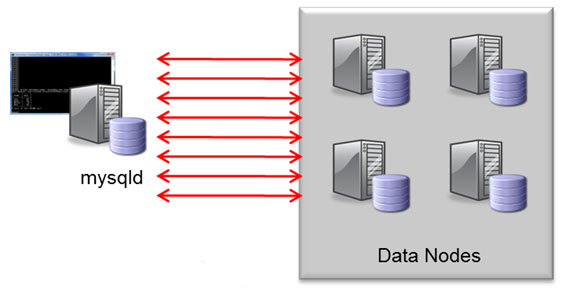
Classic Nested-Loop-Join
Traditionally, joins have been implemented in the MySQL Server where the query was executed. This is implemented as a nested-loop join; for every row from the first part of the join, a request has to be sent to the data nodes in order to fetch the data for the next level of the join and for every row in that level…. This method can result in a lot of network messages which slows down the query (as well as wasting resources). When turned on, Adaptive Query Localization results in the hard work being pushed down to the data nodes where the data is locally accessible. As a bonus, the work is divided amongst the pool of data nodes and so you get parallel execution.
{kind=link}
NDB API
I’ll leave the real deep and dirty details to others but cover the basic concepts here. All API nodes access the data nodes using the native C++ NDB API, the MySQL Server is one example of an API node (the new Memcached Cluster API is another). This API has been expanded to allow parameterised or linked queries where the input from one query is dependent on the previous one. To borrow an example from an excellent post by Frazer Clement on the topic, the classic way to implement a join would be…
SQL > select t1.b, t2.c from t1,t2 where t1.pk=22 and t1.b=t2.pk; ndbapi > read column b from t1 where pk = 22;
[round trip]
(b = 15) ndbapi > read column c from t2 where pk = 15;
[round trip]
(c = 30)
[ return b = 15, c = 30 ]
Using the new functionality this can be performed with a single network round trip where the second read operation is dependent on the results of the first…
ndbapi > read column @b:=b from t1 where pk = 22;
read column c from t2 where pk=@b;
[round trip]
(b = 15, c = 30)
[ return b = 15, c = 30 ]
You can check whether your query is fitting these rules using EXPLAIN, for example:
mysql> set ndb_join_pushdown=on;
mysql> EXPLAIN SELECT COUNT(*) FROM residents,postcodes WHERE residents.postcode=postcodes.postcode AND postcodes.town="MAIDENHEAD"; +----+-------------+-----------+--------+---------------+---------+---------+------------------------------+--------+--------------------------------------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+--------+---------------+---------+---------+------------------------------+--------+--------------------------------------------------------------------------+ | 1 | SIMPLE | residents | ALL | NULL | NULL | NULL | NULL | 100000 | Parent of 2 pushed join@1 | | 1 | SIMPLE | postcodes | eq_ref | PRIMARY | PRIMARY | 22 | clusterdb.residents.postcode | 1 | Child of 'residents' in pushed join@1; Using where with pushed condition | +----+-------------+-----------+--------+---------------+---------+---------+------------------------------+--------+--------------------------------------------------------------------------+
mysql> EXPLAIN EXTENDED SELECT COUNT(*) FROM residents,postcodes,towns WHERE residents.postcode=postcodes.postcode AND postcodes.town=towns.town AND towns.county="Berkshire"; +----+-------------+-----------+--------+---------------+---------+---------+------------------------------+--------+----------+------------------------------------------------------------------------------------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+--------+---------------+---------+---------+------------------------------+--------+----------+------------------------------------------------------------------------------------------------------------------------+ | 1 | SIMPLE | residents | ALL | NULL | NULL | NULL | NULL | 100000 | 100.00 | Parent of 3 pushed join@1 | | 1 | SIMPLE | postcodes | eq_ref | PRIMARY | PRIMARY | 22 | clusterdb.residents.postcode | 1 | 100.00 | Child of 'residents' in pushed join@1 | | 1 | SIMPLE | towns | eq_ref | PRIMARY | PRIMARY | 22 | clusterdb.postcodes.town | 1 | 100.00 | Child of 'postcodes' in pushed join@1; Using where with pushed condition: (`clusterdb`.`towns`.`county` = 'Berkshire') | +----+-------------+-----------+--------+---------------+---------+---------+------------------------------+--------+----------+------------------------------------------------------------------------------------------------------------------------+
Note that if you want to check for more details why your join isn’t currently being pushed down to the data node then you can use “EXPLAIN EXTENDED” and then “SHOW WARNINGS” to get more hints. Hopefully that will allow you to tweak your queries to get the best improvements.
PLEASE let us know your experiences and give us examples of queries that worked well and (just as importantly) those that didn’t so that we can improve the feature – just leave a comment on this Blog with your table schemas, your query and your before/after timings.