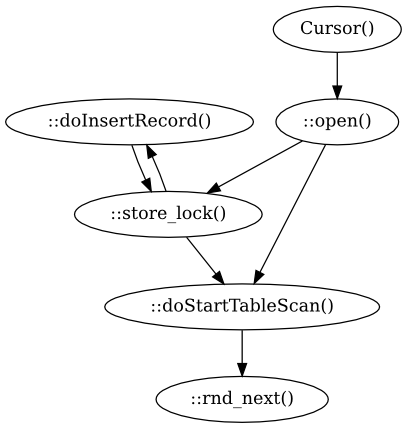
Whenever I stick my head into the MySQL storage engine API, I’m reminded of a MySQL User Conference from several years ago now.
Specifically, I’m reminded of a slide from an early talk at the MySQL User Conference by Paul McCullagh describing developing PBXT. For “How to write a Storage Engine for MySQL”, it went something like this:
- Develop basic INSERT (write_row) support – INSERT INTO t1 VALUES (42)
- Develop full table scan (rnd_init, rnd_next, rnd_end) - SELECT * from t1
- If you’re sane, stop here.
A lot of people stop at step 3. It’s a really good place to stop too. It avoids most of the tricky parts that are unexpected, undocumented and unlogical (yes, I’m inventing words here).
{kind=link}
{kind=link}