The MySQL Cluster engineering team recently ran a live webinar, available now on-demand demonstrating the ClusterJ and ClusterJPA NoSQL APIs for MySQL Cluster, and how these can be used in building real-time, high scale Java-based services that require continuous availability.
Attendees asked a number of great questions during the webinar, and I thought it would be useful to share those here, so others are also able to learn more about the Java NoSQL APIs.
First, a little bit about why we developed these APIs and why they are interesting to Java developers.
ClusterJ and Cluster JPA
ClusterJ is a Java interface to MySQL Cluster that provides either a static or dynamic domain object model, similar to the data model used by JDO, …
[Read more]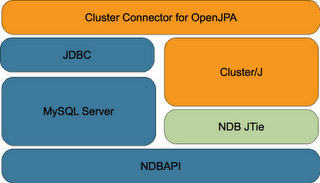{kind=link}