MySQL Cluster 7.3 has now been declared GA! This means that you can deploy it in your live systems and get support from Oracle.
{kind=link}
This post briefly describes the main new features in the release; for a deeper dive, refer to the What’s new in MySQL Cluster 7.3 white paper and the more specialised blog posts that you’ll find links to from this post.
I’ll also be giving more details in the MySQL Cluster 7.3 Webinar which is scheduled for 09:00 Pacific / Noon Eastern / 17:00 UK / 18:00 CET this Thursday (20th June). This is a great opportunity to get your questions answered in real-time by the experts. As usual, the webinar is free but you should n the register here ahead of time. Even if you can’t attend it’s worth registering as you’ll then be sent a link to the replay.
MySQL Cluster Auto-Installer
{kind=link}
MySQL Cluster Auto-Installer
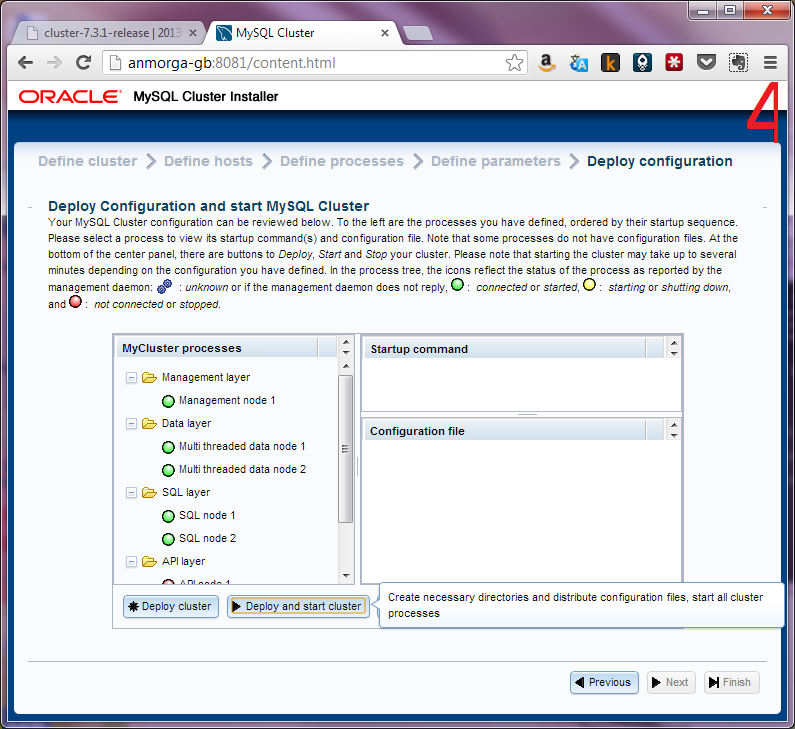
The MySQL Cluster Auto-Installer is a browser-based GUI that will provision a well configured, distributed Cluster in minutes, ready for test, development or production environments.
A major priority for this release is to make it much easier and faster to provision a cluster that is well tuned for your application and environment; we want you to focus on exploiting the benefits of MySQL Cluster in your application rather than on figuring out how to install, configure and start the database. The MySQL Cluster Auto-Installer provides a browser-based GUI which steps you through creating a Cluster tailored to your requirements. For a really good view of how the tool works, a tutorial video and detailed worked example is available from the blog post: MySQL Cluster 7.3 MySQL Cluster Auto-Installer.
Foreign Keys
{kind=link}
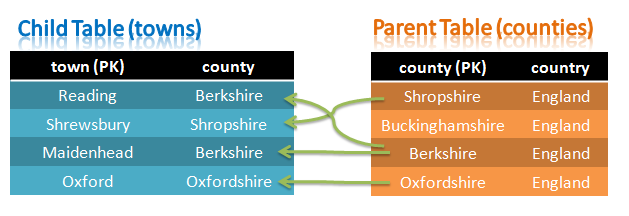
Tables with Foreign Key constraint
Foreign Keys (FKs) are a way of implementing relationships/constraints between columns in different tables. For example if we want to make sure that the value of the county column in the towns table has an associated entry in the counties table. In this way, no-one can place a town in a non-existent county and similarly no one can remove a county and leave orphaned towns behind.
We believe that this is going to enable a whole new set of applications exploit the advantages of MySQL Cluster where:
- Developers want to simplify their application by pushing referential checks down into the database
- The application is built upon 3rd party middleware that is dependent on FKs
- The application is already so dependent on FKs that it would be too complex to remove them
Note that the FK constraints will be applied regardless of how data is subsequently written (i.e. through SQL or any of the available NoSQL APIs that bypass the MySQL Server) – this ensures that the intended data integrity is always maintained.
More details and a worked example of using Foreign Keys with MySQL Cluster can be found in this post: Foreign Keys in MySQL Cluster.
JavaScript Driver for Node.js
Node.js is a platform that allows fast, scalable network applications (typically web applications) to be developed using JavaScript. Node.js is designed for a single thread to serve millions of client connections in real-time – this is achieved by an asynchronous, event-driven architecture – just like MySQL Cluster, making them a great match.
{kind=link}
The MySQL Cluster NoSQL Driver for Node.js is implemented as a module for the V8 engine, providing Node.js with a native, asynchronous JavaScript interface that can be used to both query and receive results sets directly from MySQL Cluster, without transformations to SQL. As an added benefit, you can direct the driver to use SQL so that the same API can be used with InnoDB tables.
With the MySQL Cluster JavaScript Driver for Node.js, architects can re-use JavaScript from the client to the server, all the way through to a distributed, fault-tolerant, transactional database supporting real-time, high-scale services.
Developing an application to use this API is very straightforward and an example application with full setup instructions is provided in the post Using JavaScript and Node.js with MySQL Cluster – First steps.
Connection Thread scalability
MySQL Cluster thrives when it is offered as many operations in parallel as possible. To achieve this, parallelism should be configured at each layer. There should be multiple application threads sending work to the MySQL Server (or other API), there should be multiple MySQL Servers and finally multiple connections between the MySQL Server (or other API node) and the data nodes. This is explained in more detail in the MySQL Cluster Performance white paper.
{kind=link}
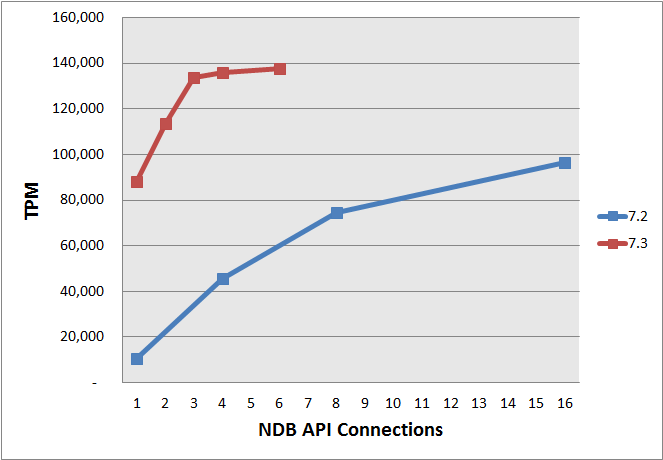
Increased throughput with Connection Thread Scalability
Each of the connections to the data nodes consumes one of the 256 available node-ids and so in some scenarios they could cap the scalability of the Cluster. MySQL Cluster 7.3 greatly increases the throughput of each of these connections meaning that less connections (and therefore node-ids) are needed to tackle the same workload; this in turn means that more API nodes and data nodes can be added to the Cluster to scale the capacity and performance even further. Benchmarks have shown up to a 8x increase in throughput per connection. The graph illustrates how less NDB API connection threads in MySQL Cluster 7.3 can deliver increased throughput compared with MySQL Cluster 7.2; the benchmark was based on DBT2 using a single data node; a single MySQL Server and 128 client connections. MySQL 5.6 Server
MySQL Cluster 7.3 also rebases onto MySQL 5.6. What this means is that the MySQL Server that comes with MySQL Cluster 7.3 is based on MySQL 5.6. This in turn means that when you mix and match MySQL Cluster (NDB) and InnoDB tables, you’ll be getting the benefits of the latest and greatest version of each storage engine.
Try it out!
Please go ahead and download and start experimenting with MySQL Cluster 7.3. We look forward to hearing how you get on!