One little bit of wisdom I would like to pass on:
If a program runs fast with 20 threads, that does not mean it
will run fast with 50. And if it runs fast with 50, it does not
mean that it will run fast with 100, and if it runs fast with 100
... don't bet on it running fast with 200 :)
In my last blog I discussed some improvement to the
performance of PBXT running the DBT2 benchmark. Despite the
overall significant increase in performance I noted a drop off at
32 threads that indicated a scaling problem. For the last couple
of weeks I have been working on this problem and I have managed
to fix it:
As before, this test was done using MySQL
5.1.30 on an 8 core, 64-bit, Linux machine with an SSD drive and
a 5 warehouse DBT2 …
{kind=link}
As a long time DBA and Database Architect this idea is repugnant – make a database 100% de-normalized; one table and except for the one query, retrieval by primary key, nothing else works. And yet we have had great success using this kind of database.
This does not replace the original normalized database, rather it is more like a permeant cache fed from the main database. It is a MySQL database which has certain advantages over Memcached or other true caches such as it is permanent until our processes replace it.
Consider what it might take to build a simple web page: get a request, process it which might take many queries and some significant processing then send back your html.
[Read more]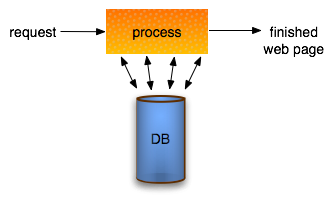{kind=link}
Sun decided to not go down the route of reviewing and accepting the patches, but are now suggesting - are you sitting down? - running multiple instances on the same hardware.
I just came upon a pretty good Hadoop introduction paper posted on Sunâ€s wiki. Apache Hadoop is a free Java software framework that supports data intensive distributed applications. It enables applications to work with thousands of nodes and petabytes of data. Hadoop was inspired by Google's MapReduce and Google File System (GFS) (wikipedia). I wouldnâ€t call it an alternative to mysql – theyâ€re in completely different weight categories. I like …
[Read more]{kind=link}
In a lot of environments.
Peter gives a nice overview why you don't always need to invest in big fat redundant hardware.
We've tackled the topic last year already ..
Now I often get weird looks when I dare to mention that Raid is obsolete ..people fail to hear the "in a lot of environments"
Obviously the catch is in the second part, you won't be doing this for your small shop around the corner with just one machine. You'll only be doing this in an environment where you can work with a redundant array of inexpensive disks. Not with a server that has to sit in a remote and isolated location.
Next to that there are situations where you will be using raid, but not for redundancy, but for disk throughput.
First of all let me start off saying that I learned a lot of
Capacity Planning from two people. Jozo Dujmovic, and John Allspaw-who by
the way is coming out with a book.
Capacity != Performance. You may have the capacity to do a
bubble sort but a bubble sort is still a bubble sort.
Really to Scale you need to know when your application will
break. I have a tool set to help determine what application is
producing what SQL and use that to figure out which SQL is
producing the most load on the system. Some common tricks I do is
put the execution path automatically as a SQL comment, then
sample the FULL Processlist to build a graph on what application,
function, SQL pattern is the top load.
On top of that I use Ganglia to trend the use of each mysql …
This post is SEO bait for people trying to scale MySQL’s write capacity by writing to both servers in master-master replication. The short answer: you can’t do it. It’s impossible.
I keep hearing this line of reasoning: “if I make a MySQL replication ‘cluster’ and move half the writes to machine A and half of them to machine B, I can increase my overall write capacity.” It’s a fallacy. All writes are repeated on both machines: the writes you do on machine A are repeated via replication on machine B, and vice versa. You don’t shield either machine from any of the load.
In addition, doing this introduces a very dangerous side effect: in case of a problem, neither machine has the authoritative data. Neither machine’s data can be trusted, but neither machine’s data can be discarded either. This is a very difficult situation to recover from. Save yourself grief, work, and money. Never write to both …
[Read more]My editor Andy Oram recently sent me an ACM article on BASE, a technique for improving scalability by being willing to give up some other properties of traditional transactional systems.
It’s a really good read. In many ways it is the same religion everyone who’s successfully scaled a system Really Really Big has advocated. But this is different: it’s a very clear article, with a great writing style that really cuts out the fat and teaches the principles without being specific to any environment or sounding egotistical.
He mentions a lot of current thinking in the field, including the CAP principle, which Robert Hodges of Continuent first turned me onto a couple months ago. …
[Read more]
Over the last few weeks I have been doing some work on improving
the concurrency performance of PBXT. The last Alpha version (1.0.03) has
quite a few problems in this area.
Most of the problems have been with r/w lock and mutex contention
but, I soon discovered that MySQL has some serious problems of
it's own. In fact, I had to remove some of the bottlenecks in
MySQL in order to continue the optimization of PBXT.
The result for simple SELECT performance is shown in the graph
below.
Here you can see that the gain is over 60% for 32
or more concurrent threads. Both results show the performance
with the newly optimized version of PBXT. The test is running on
a 2.16 MHz dual core processor, so I expect an even greater
improvement on 4 or 8 cores. The query I ran for this test is …
{kind=link}
At the MySQL Conference & Expo 2008, Britt Crawford and Justin McCarthy, both from Cafepress.com, gave us a very interesting talk on scaling with HiveDB. I took a few notes (pasted below), their slides are online (warning: 6.1MB PDF), and if you’re after their abstract its available as well.
I also took a video of them (refer to Slide 12, for the IRC conversation):
The quick notes:
- OLTP optimised (as it serves cafepress.com)
- Cannot lock tables, or take it offline
- Constant response time is more important than low latency (little slower query is ok, just not exponentially …