It was a year ago, on a nice Sunday night of the English Summer
(apologies for the oxymoron), that Mark
Riddoch came to see me and together we headed to the Vansittart
Arms, our local family pub round the corner. A pint of
London Pride on one side and a Honey
Dew on the other were the perfect add-on to Mark’s MacBook
Pro, on which Mark was showing me the 0.1 version of MaxScale. It
was the result of the joint efforts of Mark’s team, Massimiliano
and Vilho, who had worked hard to bring to life the first version
of something that I believe will be a natural addition to
clusters of MySQL/Percona/MariaDB servers in the near
future.
A year ago, Mark showed me a basic debugging interface for
MaxScale. We went through some parts of the code and the internal
structures, and we looked at the way his team had kept everything
sleek and lightweight. It was the implementation of hours and
hours spent jotting ideas, diagrams, comments from users and
customers. We spent hours at Caffe Trieste
in San Francisco, at the Google Campus and at the National
Theatre in London, in Berlin with my friend Kris and in many
busy airports around Europe and US. Last but not least, the
whiteboard in my garden office had been filled and wiped hundreds
of times in order to try and find good ideas and the right
components for MaxScale.
Today MaxScale has reached its beta stage. It is like a birthday,
not only because a year has passed and we have reached a certain
level of maturity, but mainly because, as it happens for humans,
we like to set milestones in order to better organise our life
and our work, and to set and achieve goals. But MaxScale is
already evolving from 1.0: the code in various branches on
GitHub is already showing more interesting and
exciting features, which the team is developing for the next
versions.
What is important and I want to talk about today is what is
available in the 1.0-beta. We have now a new set of modules that
are used to create filters, log queries and results, transform
the requests to the database and the data retrieved. The
read/write splitter is now available for both MySQL Replication
and Galera, opening new possibilities to scale even
better. In addition to these features, we now have dynamic
balance server weighting, Node and Session Replication
Consistency checks, automatic failover to multiple slaves and a
more clear mechanism to implement high availability for MaxScale
itself.
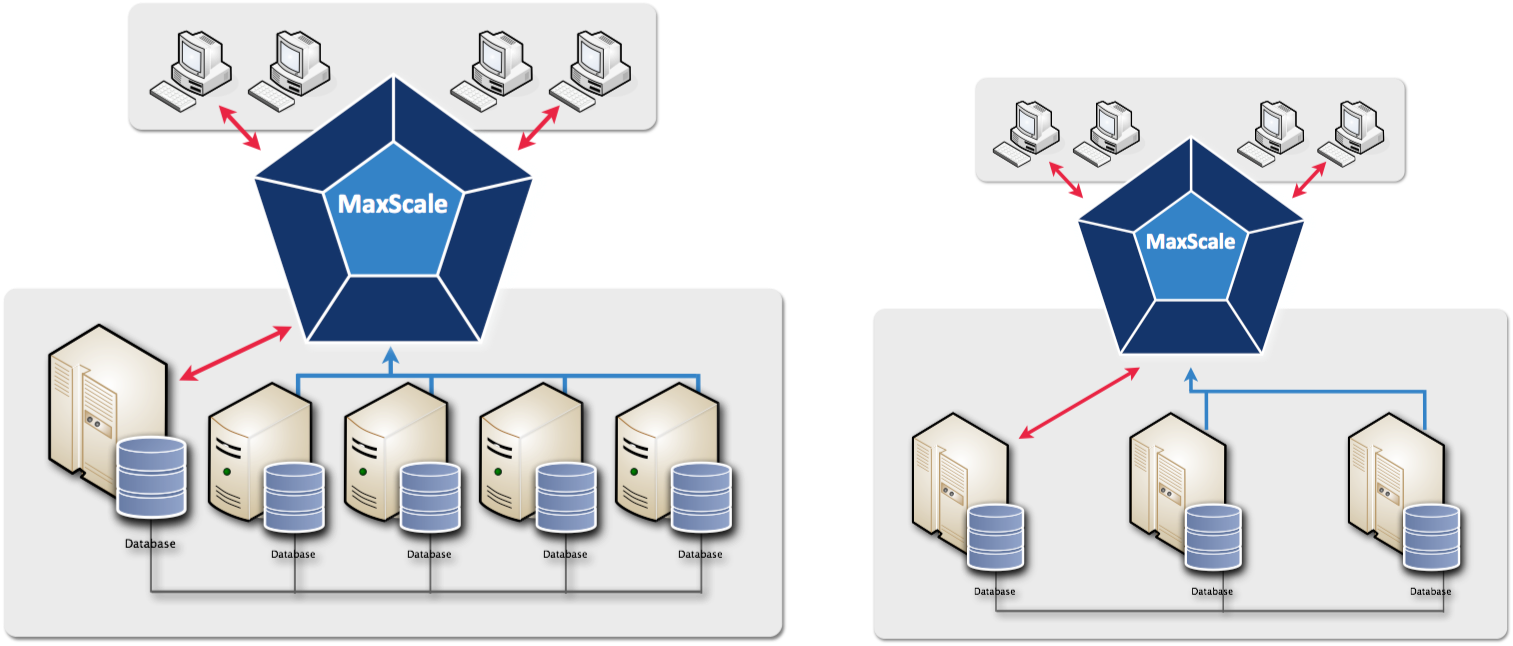
Let’s stick to the basics For those who do not know MaxScale yet, here
is the 60 seconds pitch. MaxScale is a database-centric proxy. It
is "database centric" because it has been designed with database
operations in mind, covering the typical I/O, computation and
resource management of a databases. “Proxy" means that it sits
between two components of a data infrastructure, where at least
one of these components is a database. This means that MaxScale
can sit between a client and one or more database servers,
between a database master and one or more database slaves, or
between two or more paired databases.
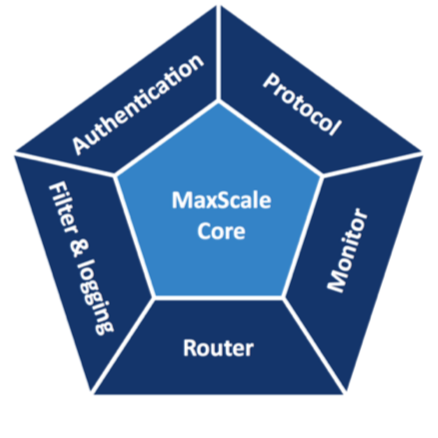
MaxScale's core is based in Linux
epoll calls and is optimised to be lightweight and low
latency. MaxScale's architecture relies on the use of pluggable
modules that are combined together to offer authentication,
protocol management, filtering, logging, monitoring and routing.
In simple terms, the opportunities are endless: you simply need
to define your objective and know the MaxScale API to build a
proxy system that will take care of the communication and the
resource usage of its components.
{kind=link}
|
MaxScale as a proxy between client
applications and a cluster of MySQL and
MariaDB Replication servers and Galera
Cluster. Red lines are read/write, blue lines are
read/only. |
{kind=link}
MaxScale 1.0 beta comes with a set of interesting modules:
- Authentication: MySQL/MariaDB authentication is operated inside MaxScale and the authentication to one or more servers is executed asynchronously. This module reduces the overall latency, especially when MaxScale is co-located with the application server.
- Protocol: MaxScale provides client and backend MySQL connectivity.
- Monitoring: MaxScale 1.0 beta comes with monitoring modules that are designed to work with single MySQL, Percona and MariaDB servers, with MySQL and MariaDB Replication and with Galera-based clusters.
- Filter & Logging: this is the last addition to the set of modules in MaxScale. There are now some interesting logging modules used to monitor queries and results, and to transform queries captured using regular expressions.
- Routing: MaxScale 1.0 beta comes with 2 routing modules, one to load-balance read/only connections on slave nodes or to load-balance read/write connections to Galera nodes, and another to route statements on nodes that are part of MySQL, MariaDB Replication and Galera-based clusters.
| High availability for MaxScale: redundant MaxScales and co-location with the application servers. |
{kind=link}
You can find more details on the modules in Mark
Riddoch’s blog posts.
Why a Proxy?You may have seen the latest announcements from
Oracle regarding a long-awaited and great product, MySQL Fabric. Fabric proudly claims to be
proxy-free, and people usually ask me to compare MaxScale with
Fabric and what the pros and cons of the two products are. First
of all, I believe these products serve different scopes and they
overlap only for a small set of features.
Fabric, as Oracle says in the first sentence of its web page is a framework for managing a farm of
MySQL Servers. The focus is on the management of a number of
servers that work together to provide a database infrastructure
for your application. The servers are mapped together to provide
availability and scalability, for example through database
sharding. In order to use Fabric, you must upgrade to the newest
versions of your database connectors and servers. For some
applications, you may also need to modify the code in order to
use some Fabric features (for example when Fabric is used with
MySQL Replication, in order to load balance workload on read
slaves).
MaxScale is meant to be a dispatcher of your database
communications. In doing so, MaxScale can reduce the number of
I/O ops, log and modify queries and results, and optimize the use
of the database servers. MaxScale is designed to work
transparently with all the connectors and database servers from
version 4.1 to the latest MariaDB 10.X, and to react in real time
to the requests of the clients, to the current workload and to
the status of the database infrastructure. By doing so, MaxScale
offers better availability and scalability - you may say, like
Fabric does, but looking at what scalability and availability
means, MaxScale is focused on the optimal use of the database
servers (for example with a continuous monitoring of the database
workload), instead of looking at a farm of servers as a
whole.
The first baby stepThis is the first baby step for MaxScale and
users are warned that there is still a lot of work to do to
improve it and to make it more stable. The fact that MaxScale is
now beta means that it has reached a maturity in terms of
features and many bugs have been fixed in the last 6 months, but
the product is not production ready yet, unless used in a
thoroughly tested and conso
lidated environment, i.e. where no changes in terms of versions
or features are applied to the database and application servers.
The next months will be devoted to catch more bugs, to benchmark
MaxScale on real cases and in extreme conditions, such as heavy
workloads in typical web-based applications for social
networking, e-commerce, gaming and collaboration. The next
objective is of course to see a robust version that can be
declared production ready, i.e. in common terms we have
thoroughly tested on live environments and we have caught and
fixed all the known P1 & P2 bugs.
As usual, there is more to come, but in the meantime, we need
your help to improve MaxScale - you can find the source code
here (warning: the build is not optimal yet!). The
fuss-free compiled versions are here. maxscale@googlegroups.com is now
very active, we have many people who submit comments and requests
every day, and this is already a success per se.