Here are examples comparing MySQL 5.6 against PostgreSQL 9.3 Core Distribution, where MySQL seems to comply with "standard SQL" more closely than PostgreSQL does. The examples are also true for MariaDB 10.0 so whenever I say "MySQL" I mean "MySQL and/or MariaDB". When I say "more closely" I do not mean that MySQL is completely compliant, or that PostgreSQL is completely non-compliant.
Identifiers
Example:
CREATE TABLE ŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽ (s1 INT); /* 32-character name */
SELECT COUNT(*) FROM information_schema.tables
WHERE table_name = 'ŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽ';
SELECT COUNT(*) FROM information_schema.tables
WHERE table_name LIKE LOWER('Ž%');
Result:
PostgreSQL says count(*) is 0. MySQL says it's 1.
Reason:
(1) PostgreSQL maximum identifier length is 63 bytes; MySQL
maximum identifier length is 64 characters. The standard
requirement is 128 characters.
(2) With PostgreSQL, if you insert an invalid value, PostgreSQL
truncates -- it "tries to make do" rather than failing. (If the
name had been too long for MySQL, it would have thrown an
error.)
(3) PostgreSQL does not convert to lower case during CREATE, and
does a case-sensitive search during SELECT.
Character Sets And Collations
Example:
CREATE TABLE t (s1 CHAR(1) CHARACTER SET utf16);
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL does not support named character sets; it can only
handle one character set per database.
Example:
CREATE TABLE t (s1 CHAR(2), s2 VARCHAR(2));
INSERT INTO t VALUES ('y ','y ');
SELECT * FROM t WHERE s1 = 'y';
SELECT * FROM t WHERE s2 = 'y';
Result:
PostgreSQL finds one row for the first SELECT but zero rows for
the second SELECT. MySQL finds one row both times.
Reason:
PostgreSQL does not always add spaces to the shorter comparand,
or remove spaces from the longer comparand. MySQL is consistent.
The behaviour is optional, but it is not supposed to depend on
the data type.
Example:
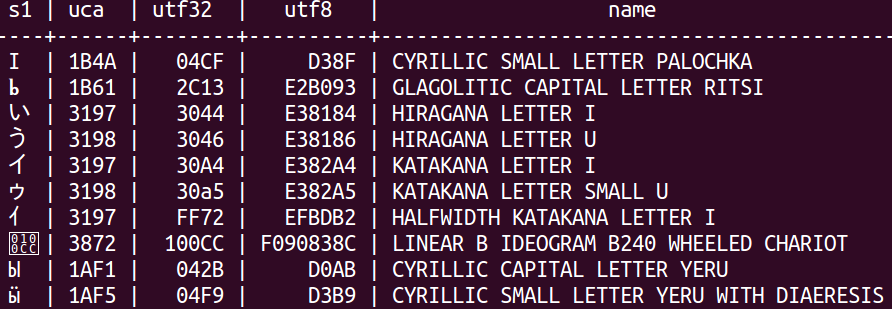
CREATE TABLE t (s1 CHAR(1), uca CHAR(4),utf32 CHAR(6),utf8 CHAR(8),name VARCHAR(50)); INSERT INTO t VALUES (U&'\+003044','3197',' 3044',' E38184','HIRAGANA LETTER I'); INSERT INTO t VALUES (U&'\+003046','3198',' 3046',' E38186','HIRAGANA LETTER U'); INSERT INTO t VALUES (U&'\+0030A4','3197',' 30A4',' E382A4','KATAKANA LETTER I'); INSERT INTO t VALUES (U&'\+0030A5','3198',' 30a5',' E382A5','KATAKANA LETTER SMALL U'); INSERT INTO t VALUES (U&'\+00FF72','3197',' FF72',' EFBDB2','HALFWIDTH KATAKANA LETTER I'); INSERT INTO t VALUES (U&'\+00042B','1AF1',' 042B',' D0AB','CYRILLIC CAPITAL LETTER YERU'); INSERT INTO t VALUES (U&'\+0004F9','1AF5',' 04F9',' D3B9','CYRILLIC SMALL LETTER YERU WITH DIAERESIS'); INSERT INTO t VALUES (U&'\+0004CF','1B4A',' 04CF',' D38F','CYRILLIC SMALL LETTER PALOCHKA'); INSERT INTO t VALUES (U&'\+002C13','1B61',' 2C13',' E2B093','GLAGOLITIC CAPITAL LETTER RITSI'); INSERT INTO t VALUES (U&'\+0100CC','3872',' 100CC','F090838C','LINEAR B IDEOGRAM B240 WHEELED CHARIOT'); SELECT * FROM t ORDER BY s1 COLLATE "C",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "POSIX",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "C.UTF-8",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "en_CA.utf8",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "default",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "ucs_basic",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "zh_CN",uca DESC,name;
Result:
With PostgreSQL, no matter which collation one chooses, one does
not get a linguistic standard ordering. Here is a typical
result:
With MySQL, if one enters the same data (albeit in a different
way), and chooses collation utf8mb4_unicode_520_ci, one gets a
standard result.
Reason:
PostgreSQL depends on the operating system for its collations. In
this case my Linux operating system offered me only 5 collations
which were really distinct. I did not attempt to customize or add
more. I tried all the ones that were supplied, and failed to get
a result which would match the Unicode Collation Algorithm order
(indicated by the 'uca' column in the example). This matters
because the standard does ask for a UNICODE collation "in which
the ordering is determined by applying the Unicode Collation
Algorithm with the Default Unicode Collation Element Table
[DUCET]". MySQL is a cross-platform DBMS and does not depend on
the operating system for its collations. So, out of the box and
for all platform versions, it has about 25 distinct collations
for 4-byte UTF8. One of them is based on the DUCET for Unicode
5.2.
{kind=link}
MySQL's character set and collation support is excellent in some other respects, but I'll put off the paeans for another post. Here I've just addressed a standard matter.
Views
Example:
CREATE TABLE t (s1 INT); CREATE VIEW v AS SELECT * FROM t WHERE s1 < 5 WITH CHECK OPTION;
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
MySQL has some support for core standard feature F311-04 "Create
view: with check option". PostgreSQL does not.
Transactions
Example:
START TRANSACTION; CREATE TABLE t (s1 SMALLINT); INSERT INTO t VALUES (1); INSERT INTO t VALUES (32768); /* This causes an error. */ COMMIT; SELECT * FROM t;
Result:
MySQL finds a row containing 1. PostgreSQL finds nothing.
Reason:
PostgreSQL rolls back the entire transaction when it encounters a
syntax error. MySQL only cancels the statement.
Now, PostgreSQL is within its rights -- the standard says that an
implementor may do an "implicit rollback" for an error. But that
is a provision for what a DBMS implementor MAY do. From other
passages in the standard, it's apparent that the makers didn't
anticipate that a DBMS would ALWAYS do it, even for syntax
errors. (For example it says: "exception conditions for
transaction rollback have precedence over exception conditions
for statement failure".) Even Microsoft SQL Server, in its
optional "abort-transaction-on-error" mode, doesn't abort
for syntax errors. So MySQL appears to be nearer the spirit of
the standard as generally understood.
Example:
size=-1>CREATE TABLE t (s1 INT); INSERT INTO t VALUES (1); COMMIT; START TRANSACTION; SELECT CURRENT_TIMESTAMP FROM t; /* Pause 1 second. */ SELECT CURRENT_TIMESTAMP FROM t;
Result: PostgreSQL shows the same timestamp twice. MySQL shows
two different timestamps.
Reason:
PostgreSQL keeps the same time throughout a transaction; MySQL
keeps the same time throughout a statement.
The key sentences in the standard say that the result of a
datetime value function should be the time when the function is
evaluated, and "The time of evaluation of a datetime value
function during the execution of S and its activated triggers is
implementation-dependent." In other words, it's supposed to occur
during the execution of S, which stands for Statement. Of course,
this leads to arguable matters, for example what if the statement
is in a function that's invoked from another statement, or what
if the statement is within a compound statement (BEGIN/END
block)? But we don't have to answer those questions here. We just
have to observe that, for the example given here, the DBMS should
show two different timestamps. For documentation of how DB2
follows this, see ibm.com.
Stored Procedures, Functions, Triggers, Prepared Statements
Example:
size=-1>CREATE FUNCTION f () RETURNS INT RETURN 1;
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL does not support any functions, stored procedures, or
triggers with standard syntax.
Instead PostgreSQL supports Oracle syntax. This is not as bad it
sounds -- the Oracle syntax is so popular that even DB2 also has
decided to support it, optionally.
Example:
size=-1>PREPARE stmt1 FROM 'SELECT 5 FROM t';
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL doesn't support the standard syntax for PREPARE.
Data Types
Example:
size=-1>CREATE TABLE t (s1 CHAR(1)); INSERT INTO t VALUES (U&'\+000000');
Result:
PostgreSQL returns an error. MySQL succeeds, although MySQL has
to use a different non-standard syntax.
Reason:
PostgreSQL has an aversion to CHR(0) the NUL character.("The
character with the code zero cannot be in a string constant.").
Other DBMSs allow all characters in the chosen character set. In
this case, the default character set is in use, so all Unicode
characters should be okay.
Example:
size=-1>CREATE TABLE t (s1 BINARY(1), s2 VARBINARY(2), s3 BLOB);
Result: PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL does not support BINARY or VARBINARY or BLOB. It has
equivalent non-standard data types.
The Devil Can Cite Scripture For His Purpose
I could easily find examples going the other way, if I wrote a
blog post titled "Sometimes PostgreSQL is more
standards-compliant than MySQL". But can one generalize from such
examples?
The PostgreSQL folks boldly go to conclusion mode:
As a quick summary, MySQL is the "easy-to-use, web developer" database, and PostgreSQL is the "feature-rich, standards-compliant" database.
Follow I do not dare.