Global Transaction Identifiers – why, what, and how
Next post: Advanced use of Global Transaction
Identifiers
This post was kindly translated to Japanese by
Ryusuke Kajiyama.
In MySQL 5.6 we introduced a new replication feature called
Global Transaction Identifiers, or GTIDs. While there are many
use cases, our primary motivation for introducing GTIDs is that
it allows for seamless failover. By this, we mean promoting one
of the slaves to be come a master, if the master crashes, with
minimal manual intervention and service disruption.
This is the first in a series of several blog posts. We will go
through several use cases and show how easy it is to do a
failover. We explain how to do it, as well as the most important
tool for monitoring GTIDs.
Subsequent blog posts will dive further into the advanced ways to
use this powerful feature, giving a deeper understanding of the
implementation and mechanisms on the way. This will give you
greater control and allow you to easier troubleshoot and debug
your replication setup, better plan your failover before you need
it, and understand how it works together with other features.
Finally, we will go beyond GTIDs in the server and look at how
external tools can use GTIDs to implement various application
dependent policies for deciding which slave to promote to master
in a failover scenario.
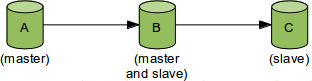
Use cases Tree topology. Let us first see what it is we
want to achieve. One of the most common replication setups, or
topologies, is one master that receives all updates from
clients and has multiple slaves. The simplest case uses three
servers: one master with two slaves, as in the following
figure:
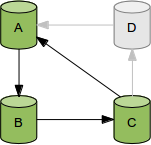
Now suppose server A crashes. We then need to
make a failover: take one of the servers B or C and make it the
master; make the remaining server a slave of that new master:
Linear topology. Another example is a
linear topology, where server A replicates to server B, B to C,
and so on. Only A receives updates from clients:
Suppose B crashes; then we want C to become a
direct slave of A. Thus, in this case the failover means that we
make a shortcut in the chain:
Circular topology. Going further, a
more interesting case is that of circular replication: Here, it is possible that all servers receive
updates. (Since replication is asynchronous, it is up to the
application logic to ensure that concurrent updates do not
conflict.) If one server crashes, we want to close the circle
again:
Arbitrary topologies. You may have
noticed that we progress to more advanced use cases and we end
this series of examples with one that is in a sense the most
generic you could think of. It is of course not necessary to
crash a server in order to change the topology. In fact, the
power of GTIDs allows us to change from anytopology into
any other topology. The only thing that the DBA needs to
do is decide which servers should be slaves of which, and then
tell it to MySQL. GTIDs take care of the rest, making it easy to
ensure that no transactions are lost or reapplied more than once
on any server.
You started with a tree topology and then realized that a circle
better suits your application? No problem – just make it a
circle.
You want to upgrade the hardware on one of your slaves, making it
more powerful than the master, and therefore switch roles between
the master and the slave? Just specify which server should be a
slave of which and it will “just work”.
What GTIDs are notAt this point we should make clear what
GTIDs don't do. They don't help detect that a server has crashed
– that has to be done by external utilities. They also have
nothing to do with the logics for deciding the new topology after
a crash, and they don't help you point your clients to a
different server than before. This is of course no omission in
the design; it is simply not the role of GTIDs (or any other
server feature) to handle these tasks. GTIDs are open to any
policies for handling these issues, and the decisions are best
made by utilities outside the core server.
In a later post in this series, we will go through some possible
policies for making these decisions. We have also implemented
some such policies in a new utility, mysqlfailover.
Anatomy of a Global Transaction IdentifierNow that we have gone
through some of the use cases, let's see what a GTID really
consists of. Let us go back to the first example:
Server A crashed and we want one of B or C to
take its place.
Since replication is asynchronous, B and C may not both have
replicated and re-executed the same number of transactions; one
may be ahead of the other. For example, suppose B is ahead of C
and suppose we chose B as the new master. Then C needs to start
replicate from the first transaction in B that it has not
applied.
This is where global transaction identifiers come in. our new
feature will assign an identifier to each transaction, so that we
can track when it is applied to each server.
Here is how it works. When the master commits a transaction, it
generates an identifier consisting of two components:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- The first component is the server's server_uuid (server_uuid
is a global variable introduced in MySQL 5.6 which holds a UUID,
i.e. a 128-bit random number generated so that the probability
that two servers in the world have the same server_uuid is so
small that we can assume every UUID is unique).
- The second component is an integer; it is 1 for the first
transaction committed on the server, 2 for the second
transaction, and so on. Much like an autoincrement column, it is
incremented by one for each commit.
The first component ensures that two transactions generated on
differentservers have different GTIDs. The second
component ensures that two transactions generated on the
sameserver have different GTIDs.
In text, we write the GTID as “UUID:N”, e.g.,
22096C54-FE03-4B44-95E7-BD3C4400AF21:4711.
Identifiers are replicated The GTID is written as an event to the
binary log prior to the transaction. Thus, it looks as
follows:
The binary log including the GTID is
replicated to the slave. When the slave reads the GTID, it makes
sure that the transaction retains the same GTID after it has been
committed on the slave. Thus, the slave does not generate a new
GTID; the slave and master differ in this respect (more
precisely: a slave thread differs from a client thread in this
respect). The exact mechanism used by the slave is important and
interesting in itself; it is the topic of the next blog post in
this series.
Global Transaction Identifiers in Action The set of identifiers
executed on a server is exposed to the user in a new, read-only,
global server variable, GTID_EXECUTED (in a pre-GA version this
variable was called GTID_DONE). GTID_EXECUTED holds the range of
identifiers that have been committed on this server, as a string.
For example, suppose the server has executed transactions with
the following identifiers:
0EB3E4DB-4C31-42E6-9F55-EEBBD608511C:1
0EB3E4DB-4C31-42E6-9F55-EEBBD608511C:2
4D8B564F-03F4-4975-856A-0E65C3105328:1
0EB3E4DB-4C31-42E6-9F55-EEBBD608511C:3
4D8B564F-03F4-4975-856A-0E65C3105328:2
Then, GTID_EXECUTED has the value:
"0EB3E4DB-4C31-42E6-9F55-EEBBD608511C:1-3,
4D8B564F-03F4-4975-856A-0E65C3105328:1-2"
Here is another example:
{kind=link}
mysql> SELECT @@GLOBAL.GTID_EXECUTED;
+------------------------+
| @@GLOBAL.GTID_EXECUTED |
+------------------------+
| |
+------------------------+
mysql> CREATE TABLE tbl (a INT);
mysql> SELECT @@GLOBAL.GTID_EXECUTED;
+----------------------------------------+
| @@GLOBAL.GTID_EXECUTED |
+----------------------------------------+
| 4D8B564F-03F4-4975-856A-0E65C3105328:1 |
+----------------------------------------+
mysql> INSERT INTO tbl VALUES (1);
mysql> INSERT INTO tbl VALUES (2);
mysql> INSERT INTO tbl VALUES (3);
mysql> SELECT @@GLOBAL.GTID_EXECUTED;
+------------------------------------------+
| @@GLOBAL.GTID_EXECUTED |
+------------------------------------------+
| 4D8B564F-03F4-4975-856A-0E65C3105328:1-4 |
+------------------------------------------+
The variable can also be used to determine if a slave is up to
date with a master, and if not, which transactions it is
missing:
master> SELECT @@GLOBAL.GTID_EXECUTED;
+------------------------------------------------+ |
@@GLOBAL.GTID_EXECUTED
|
+------------------------------------------------+
| 4D8B564F-03F4-4975-856A-0E65C3105328:1-1000000 |
+------------------------------------------------+ slave>
SELECT @@GLOBAL.GTID_EXECUTED;
+-----------------------------------------------+ |
@@GLOBAL.GTID_EXECUTED
|
+-----------------------------------------------+
| 4D8B564F-03F4-4975-856A-0E65C3105328:1-999999 |
+-----------------------------------------------+
In this example, the slave is missing one transaction from the
master; the transaction has
GTID 4D8B564F-03F4-4975-856A-0E65C3105328:1000000. If you
wish, you can now use e.g. mysqlbinlog to look up the exact
statements that constitute the transaction.
The Last Ingredient: New Replication Protocol Now we have seen
how GTIDs are generated and propagated throughout the replication
topology. We need one more ingredient to use them in failover: a
slightly modified replication protocol.
Protocol.Traditionally, when the slave connects to the
master, it requests a specific binary log file and an offset to
start from master then sends everything from that point. The new
protocol is:
- When the slave connects to the master, it sends the range of
GTIDs that the slave has executed and committed.
- The master sends all other transactions, i.e. those that the slave has not yet executed.
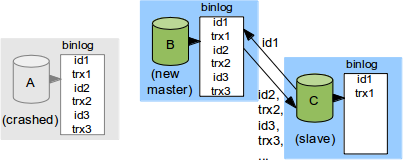
Example. The following figure illustrates the new
protocol:
Here, we have drawn the binary log of each server for clarity.
The specific SQL used in each transaction is not
important to the example; we therefore simplify a little and
write trx1, trx2, etc as abbreviations for the actual binary log
events (BEGIN, event1, event2, …, COMMIT). Moreover, the
exact UUID and sequence number that constitute
the GTID are not important either, so we abbreviate
the GTIDs as id1, id2, etc.
In our example, C will send “id1...id2” to B, and B will then
send id3, trx3 to C (and continue sending as more transactions
are committed on B).
SQL. The SQL command that tells the server to use the
new protocol is:
CHANGE MASTER TO MASTER_AUTO_POSITION = 1; Note that the DBA does
not have to specify GTIDs at all. The slave automatically sends
exactly the set of GTIDs that has been executed.
When you specify MASTER_AUTO_POSITION = 1, you cannot specify
MASTER_LOG_FILE or MASTER_LOG_POS.
Failover Finally, we are ready to see how GTIDs are used in
failover.
Tree topology. Again consider our first
example. We repeat the figure, drawing the binary logs as in the
last example:
In the figure, we have assumed that A has
executed three transactions, B has reapplied all of them, and C
is still missing the last one. A has crashed. We decide to make B
the new master, and C a slave of B.
Using the new protocol, C will send “id1” to B, and then B will
send id2, trx2 (and continue sending as more transactions are
committed on B).
Circle topology. Let us see one more example:
a case of circular replication, as in the following
picture.
Here, server B first executed transaction
trx1, then A executed trx2, and trx2 got replicated to B.
Finally, B executed trx3. Since replication is asynchronous, it
is perfectly normal that C has not yet replicated anything. If we
waited long enough, C would catch up and then A would too.
Now suppose C crashes at this point. The circle is broken and we
want to heal it by making A a direct slave of B. Using the new
protocol, A will send the identifier of its only transaction,
id2, to B. Then B will send id1, trx1, id3, trx3 to A (and when
more transactions are committed on B, B will send those
too).
Of course, it is expected that the
transactions are applied in different order on A and B at this
point; they would be in the exact same order if C had not
crashed. Again, it is the application's responsibility to ensure
that transactions sent to different servers don't conflict.
Summary To make seamless failover possible, we introduced Global
Transaction Identifiers in MySQL 5.6. GTIDs are generated when a
transaction is committed for the first time and preserved when
the transaction is replicated to other servers. The new
replication protocol makes failover nearly automatic: the DBA
does not have to know about GTIDs at all; all you have to do is
tell the slave what server is the new master. Basic monitoring is
done using @@GLOBAL.GTID_EXECUTED.
The views expressed on this blog are my own and do not
necessarily reflect the views of Oracle.
{kind=link}
{kind=link}
{kind=link}
{kind=link}