MySQL Enterprise Edition included the thread pool in its MySQL
5.5 version. We have now updated the thread pool also for the
MySQL 5.6 Enterprise Edition.
You can try it for free at trials
The MySQL thread pool is developed as a plugin and all the
interfaces needed by the thread pool are part of the MySQL
community server enabling anyone to develop their own version of
the MySQL thread pool. As part of the development of the thread
pool we did a lot of work to make it possible to deliver
stand-alone plugins using the interfaces provided by the MySQL
server. Most of these interfaces were available already in MySQL
5.1, but we extended them and made them more production ready as
part of MySQL 5.5 development. So a plugin can easily define
their own configuration variables and their own information
schema tables and also easily use performance schema extensions.
A plugin can also have its own set of tests.
Thus one can build a new plugin by adding a new directory in the
plugin directory. What is needed is then the source code of the
plugin, the tests of the plugin and finally a CMakeLists.txt-file
to describe any special things needed by the build process. The
public services published by the MySQL server is found in the
include/mysql directory. There is currently six services
published by the MySQL Server in 5.6. The my_snprintf, thd_alloc,
thd_wait, thread_scheduler, my_plugin_log and the mysql_string
services. One usually needs also to integrate a bit more of the
MySQL server as the work on modularizing the MySQL server is a
work in progress. To help other developers understand what
private interfaces are used by a plugin some plugins also provide
a plugin_name_private.h-file. There is such a file for the thread
pool and for InnoDB currently.
Buying and reading the book MySQL 5.1 Plugin Development will be
helpful if you want to develop a new MySQL server plugin. The
MySQL documentation also have a chapter on extending MySQL at
http://dev.mysql.com/doc/refman/5.6/en/extending-mysql.html
The thread pool have now been updated for the MySQL 5.6 version.
Obviously with the much higher concurrency of the MySQL Server in
5.6 it's important that the thread pool doesn't add any new
concurrency problem when scaling up to 60 CPU threads. The good
news is that the thread pool works even better in MySQL 5.6 than
in MySQL 5.5. MySQL 5.6 has fixed even more issues when it comes
to execution of many concurrent queries and this means that the
thread pool provides even more stable throughput almost
independent of the number of queries sent to it in
parallel.
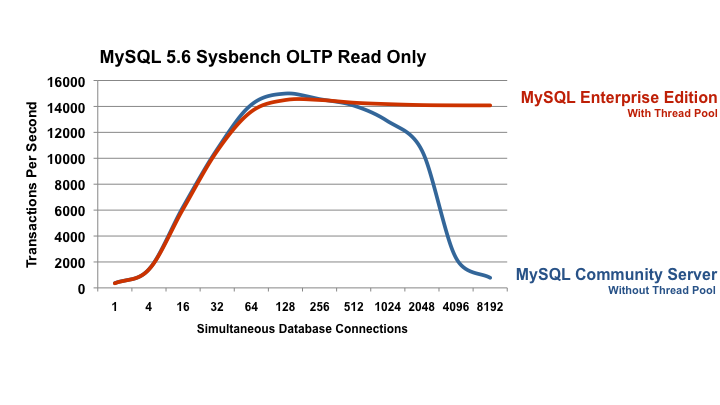
Our benchmark numbers using Sysbench OLTP RW and Sysbench OLTP RO
shows that the thread pool continues to deliver at least 97% of
the top performance even when going to 8192 concurrent queries
sent to it. The thread pool has a slight overhead of 2-3% at low
concurrency but the benefit it provides at high concurrency is
breathtaking. At 8192 concurrent queries the thread pool delivers
13x more throughput compared to standard MySQL 5.6.
So let's step back and see in which cases the thread pool is
useful. Most production servers are used at low loads most of the
time. However many web servers have high load cases where a
massive load is happening every now and then, this could be due
to more users accessing the site, but it could also be due to
changes of the web site that means that many web caches need to
be refreshed. In those cases the MySQL Servers can all of a
sudden see a burst of queries which means that the MySQL Server
has to execute thousands of queries simultaneously for a short
time.
Executing thousands of queries simultaneously is not a good use
of the computer resources. The problem is that there is a high
chance that we run out of memory in the machine and have to start
using virtual memory not resident in memory. This will have a
severe impact on the performance. Also switching between
thousands of threads means a high cost on CPU cache usage since
each time a thread is swapped in it has to build up the CPU
caches again and this means more work for the CPUs. There is also
other scalability issues within the MySQL server code that makes
contention on certain hot-spots higher when many queries are
executed concurrently.
So how does the thread pool go about resolving this problem to
ensure that the MySQL Server always operate at optimum
throughput? The first step is that when many concurrent queries
arrive that these queries are to some extent serialised, so
rather than executing all queries at once, we put the queries in
a queue and execute them one by one. Obviously there needs to be
some special handling of long-running queries to ensure that
these queries don't block short queries for too long time. Also
some special handling is needed of queries that block for some
reason such as on a row lock, a disk IO or other wait
event.
The thread pool divides connections into thread groups, the
number of thread groups is configurable, in really big machines
it can payoff to have as many as up to 60 thread groups using
MySQL 5.6. Each thread group normally executes either 0 or 1
query. Only in the case of blocked queries and long-running
queries does the thread group execute more than 1 query for a
short time.
The above description serves to avoid problems with swapping when
using too much memory and also fixes the issue with too much
context switches that taxes the CPUs.
There is however still one problem that can cause issues and this
is the fact that transactions hold resources also when no query
is running at the moment. To solve this problem the thread pool
puts a higher priority on connections that have already started a
transaction. Started transactions can hold locks on rows that
block other transactions from proceeding, they are part of
sensitive hot-spot protected regions that can slow down the
execution of all other transactions. So giving started
transactions a higher priority makes a lot of sense. Indeed this
feature means that we can sustain 97% of the optimum throughput
even in the context of 8192 concurrent queries running, without
this feature we would not be able to handle more than around 70%
of the optimum throughput at such high concurrency.
One way of describing the thread pool is as an insurance. If you
run without the thread pool your system will run just fine for
most of the time. But in the event of spike loads where the
system is taking a severe hit the thread pool serves as a
protection measure to ensure that the system continues to deliver
optimum throughput also in the context of massive amounts of
incoming queries.
The above description fits the use cases for InnoDB. It is also
possible to use the thread pool in MySQL Cluster 7.2 and onwards.
For MySQL Cluster the thread pool has a slightly different use
case. In this case the thread pool ensures that the data nodes of
MySQL Cluster are protected from overload. So setting the number
of thread groups to a number using MySQL Cluster means that this
MySQL Server can only process this number of queries concurrently
and thus ensuring that the data nodes are protected from overload
cases and also ensuring that we always operate in optimal manner.
Naturally with MySQL Cluster one can have many MySQL servers
within one cluster and thus the thread pool can provide a more
stable throughput in also highly scalable use cases of MySQL
Cluster.
May
13
2013
{kind=link}
{kind=link}