The slow query log is the trusted old method of recording slow query, so the database administrator can determine which queries are in the most need for optimization. Since MySQL 5.6, it has to some extend been overshadowed by the Performance Schema which has lower overhead and thus allows collecting statistics about all queries. The slow query log has one major advantage though: the data is persisted. In MySQL 8.0.14 which was recently released, there is an improvement for the slow query log: additional statistics about the recorded queries.
The slow query log with log_slow_extra enabled.
Contribution
Thanks for Facebook for …
[Read more]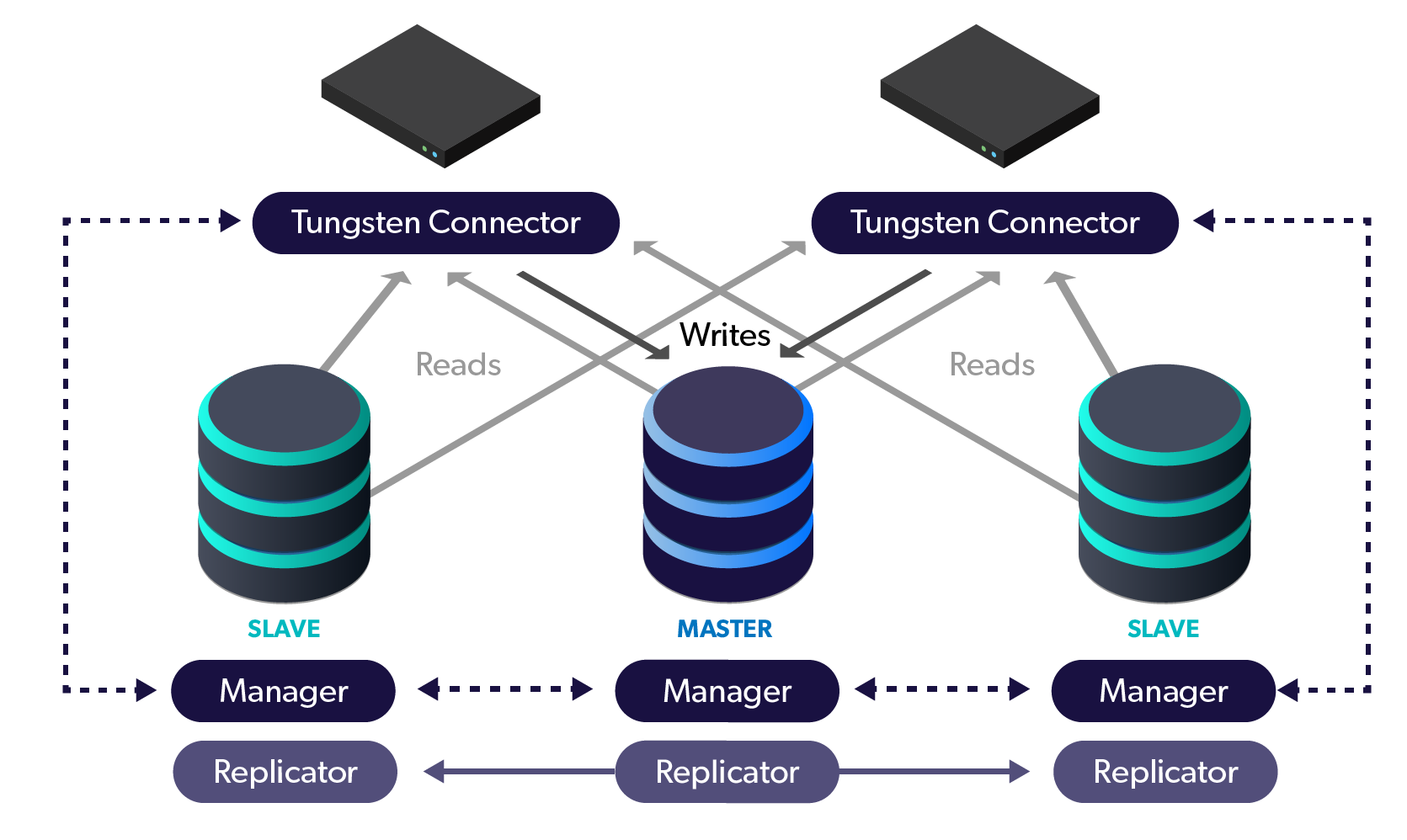{kind=link}
{kind=link}